Welcome to the third module of the Opencourseware "Bible and digital humanities" of the Catholic University of Louvain (Belgium), created thanks to a 2023 grant from the équipe Université numérique, UCLouvain. This module will present an introduction to manuscript encoding using the TEI/XML standard and HTML for webpages. It is not a practical encoding course but rather a guide to understanding what encoding is, how it is done and why. There are already many courses, tutorials, and introductions to encoding, which are more detailed than what we could see in a few minutes. The aim of this module is therefore to point you in the direction of the tools and resources that already exist to get started with XML encoding.
Introduction
Among the existing resources, I would like to mention two that serve as reference for this module:
- Digital Scholarly Editions: Manuscripts, Texts and TEI Encoding, a #dariahTeach course created in 2017 by Elena Pierazzo and Marjorie Burghart.
- What is the Text Encoding Initiative? (2015), a book by Lou Burnard who is one of the TEI co-founders.
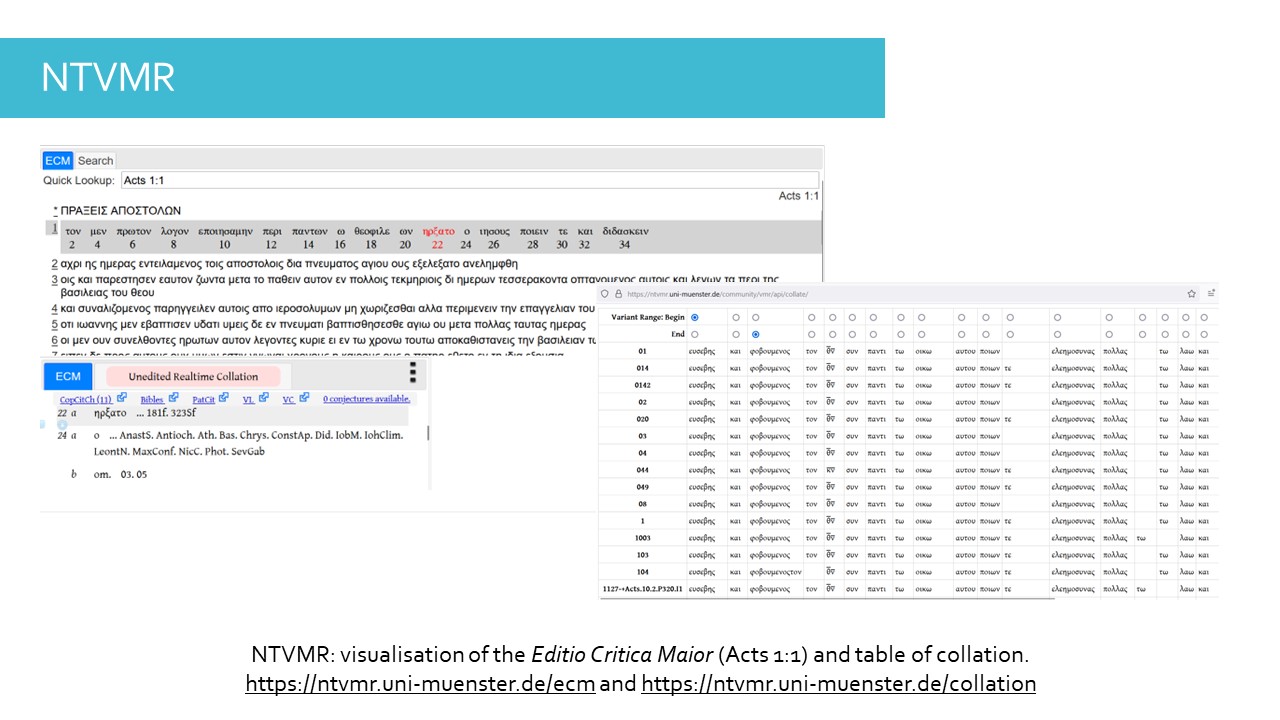
The previous module introduced the New Testament Virtual Manuscript Room (NTVMR) and the Editio Critica Maior (ECM). Tools such as the NTVMR, organised around electronic transcriptions of texts, are considered as some of the most important ones in the study of New Testament manuscripts (Allen 2019).
These new tools, which make manuscript texts and images accessible to all, are transforming the field of biblical studies research, and have fundamentally changed the methodology of editing the Greek New Testament (Houghton 2019).
A project like the NTVMR, requiring international collaboration, is made possible notably by the adoption of shared software and encoding schemes (Houghton & Smith 2016).
It is this encoding of texts that makes it possible to instantly visualise the critical apparatus of the ECM, or the multiple visualisations offered, such as the collation tables.
Some researchers even argue in favour of increasing the scope of encoding, to enable more effective searches of other manuscript features, such as their codicological description or bibliography (Smith 2021).
What is Encoding?
Encoding and its tags with pointy brackets may seem intimidating, but it's something you already do quite naturally and probably without even thinking about it when you are writing: when you use uppercase and punctuation marks, you encode the beginning and end of a sentence, you give a specific meaning to your text. A simple comma can completely change a sentence. When you increase the font size to highlight a title or subtitle, you are marking a division in the text.
This encoding makes reading much easier. For example, the oldest manuscripts are often written in “continuous script” (scriptio continua), in capitals, with no or little punctuation, or space between words. Here you have a handwritten example with the transcription next to it, and an example of what this would look like with the first verses of Genesis.
Similarly, when you read a critical apparatus, you decipher information encoded by special characters: for example, vertical bars 'encode' the separation between two apparatus entries, or between readings within an entry; substitution markers 'encode' a variant concerning either a single (⸀) or several words (⸂ and ⸃), etc.
Encoding is integrating an interpretative dimension into the text. This can be done through the organisation of the text on the page, typographical variations or special signs. But when we talk about encoding a text, in Digital Humanities, we mean encoding with a markup language, in particular XML.
The Text Encoding Initiative (TEI) is the standard of reference for encoding manuscripts. It is a set of XML elements defined by the scientific community for encoding texts, which are the primary sources in Humanities research. The TEI allows us to describe and define what we see on a manuscript page. The TEI encoding adds a semantic dimension. HTML is another mark-up language used to present text on a web page.
For example, in HTML a word will simply be encoded with an i between brackets to indicate that this word should be presented in italics. With the TEI, on the other hand, we will encode our interpretation of this text as being either an emphasis, a foreign word, an article title, or a general highlight, etc. This interpretation is independent of the way in which the text is presented on a screen but is essential for researchers who need to analyze their texts in detail.
Finally, I would like to stress that TEI encoding is not completely neutral or objective, but it does include an element of analysis. Two researchers, faced with a page of manuscript, will produce two different encodings. As Elena Pierazzo notes, “encoding also communicates an editor's understanding and interpretation of the letters on a page”. But being objective is not desirable as much as being transparent about our interpretation (Luizzo 2019).
All TEI elements are described in the TEI guidelines, available on the TEI Consortium website.
There are subsets of TEI elements adapted to a specific field of research, for instance EpiDoc, which are guidelines for encoding ancient documents such as papyri or epigraphic inscriptions.
I also strongly recommend taking the “Manuscript Transcription” module of the #dariahTeach course (videos no 7-14). This module reviews the encoding of various aspects of handwritten texts, such as abbreviations, copyist interventions (additions, deletions, substitutions), or passages that are difficult to read.
There are guidelines more specifically designed for the biblical sciences. Here I would like to mention two examples:
1. The IGNTP guidelines. These guidelines are influenced by EpiDoc and have been defined for the encoding of Greek manuscripts of the New Testament. The first version 1.1 dates back to February 2011, and the most recent is version 1.5 from 2016 by Hugh Houghton.
2. The Patristic Text Archive (PTA) guidelines. These guidelines are also inspired by EpiDoc, but modified and enriched, based on the work of Annette von Stockhausen.
These two examples give you an idea of how the TEI can be used to encode texts. We can see that the encoding problems between the Greek manuscripts of the New Testament and those of the patristic texts have given rise to different encodings, each of them valid. For example, the structure of the text for the New Testament manuscripts (section 2, “division of the work”) is different from that of the Patristic texts (section 3.4.9.1, “Encoding of the structure of the text”). The IGNTP guidelines focus more on the text and its characteristics in a specific manuscript, whereas for the Patristic archive, you will have an encoding of an edited text that also highlights quotations and biblical allusions, or “Named Entities”, that is to say the names of people and places.
To encode in TEI, you need a text editor. In principle, this can be done in any text editor – even the most basic will do – but some tools can greatly improve the encoding experience.
oXygen is the most widely used editor among researchers to encode in TEI, but it is not free. It offers very useful features such as validation, and also an “author” mode that lets you work on text without the XML tags. oXygen is considered the best editor to work with the TEI, but there are free alternatives, such as Visual Studio Code, with add-on modules dedicated to XML.
I would also like to mention two online editors that allow you to work on text as in a Word document, instead of XML with its tags.
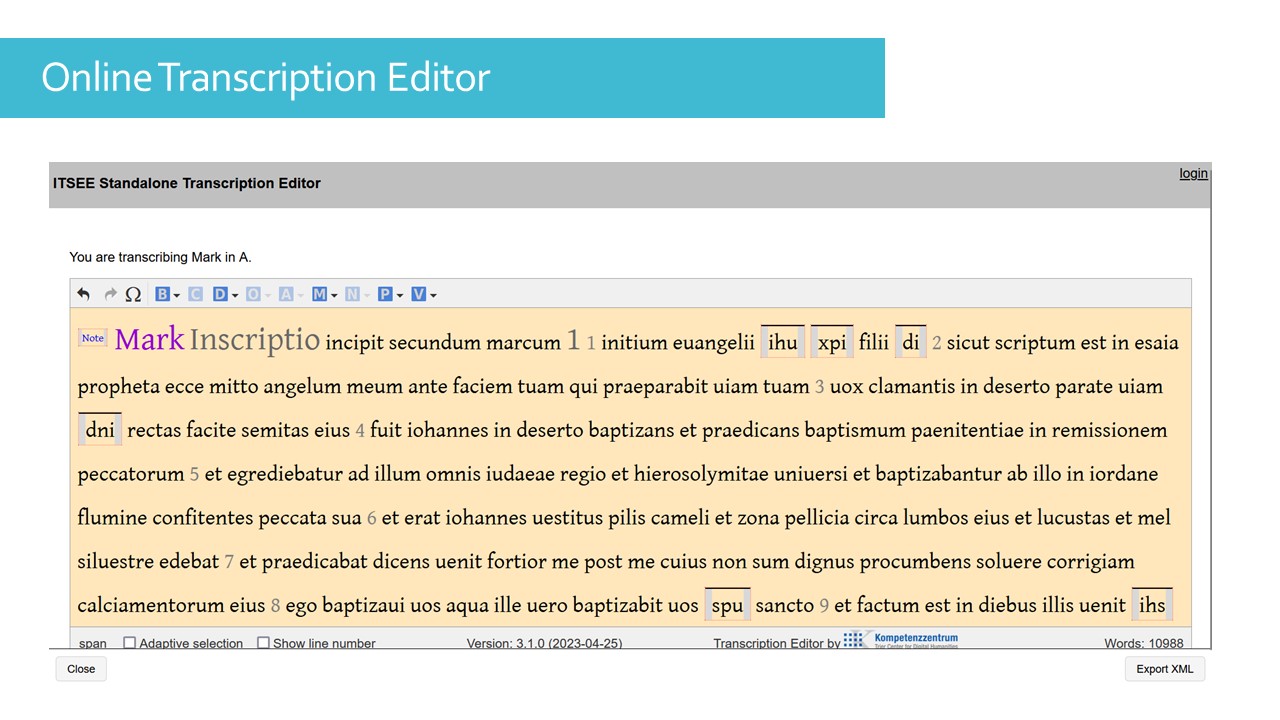
The first is the Online Transcription Editor.
This is an editor developed as part of the Workspace for Collaborative Editing project, which gave rise to the NTVMR interface. The NTVMR version allows registered users to export in HTML format. This editor is also available a standalone tool. You can choose to import a transcription or start transcribing from an existing base text and then edit it.
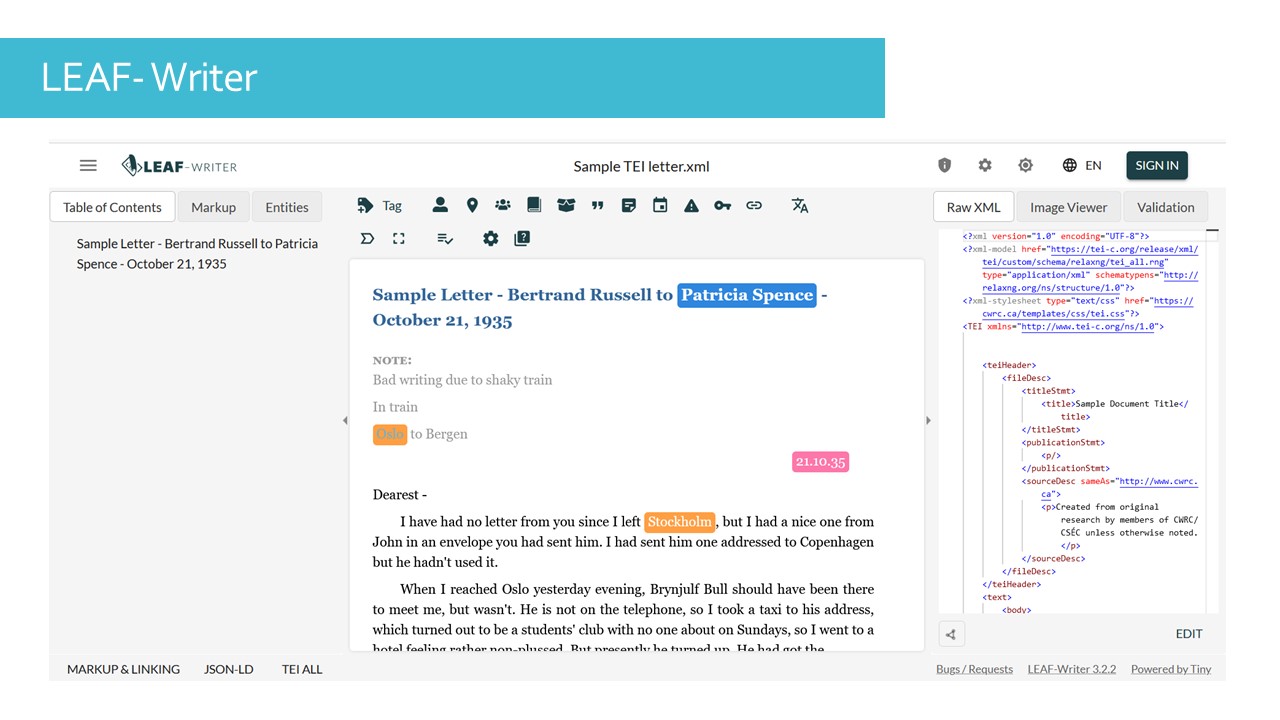
Leaf Writer is an editor stemming from a project led by Susan Brown and her team, and is designed specifically for editing texts in TEI, with a target audience broader than Biblical Studies researchers. It offers more features for working with Named Entities and Linked Open Data.
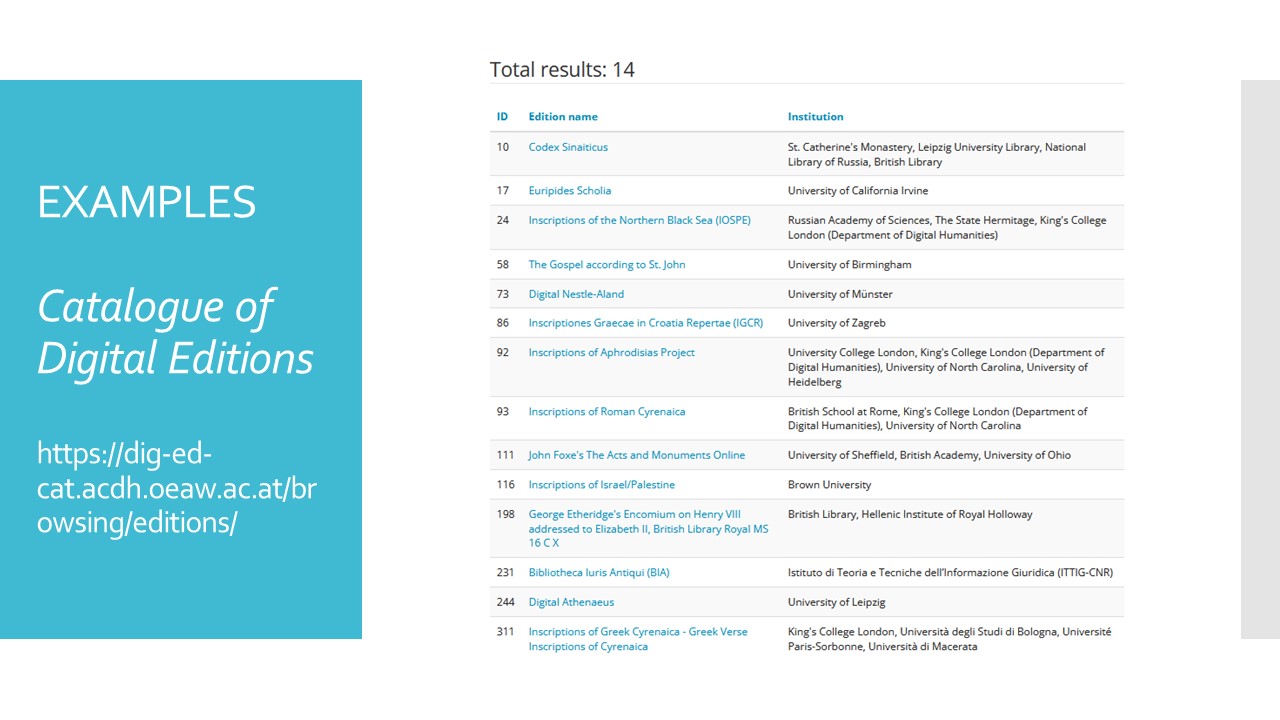
It is always useful to see examples of digital editions in TEI to see good transcription practices. A good way to search for examples is to use the Catalogue of Digital Editions. Among the advanced filters, you can select editions that have texts encoded in TEI, for example here I have chosen to see editions of Greek texts with TEI encoding.
As it is relatively easy to find examples in Greek or Latin, I would like to mention a few examples of projects that provide TEI encoding of texts in other languages found in biblical manuscripts. For instance, number 93 of the list is the Inscriptions from Israel/Palestine, a collection of epigraphic inscriptions in Greek as well as Aramaic, Armenian, Georgian, Hebrew, Phoenician, etc.
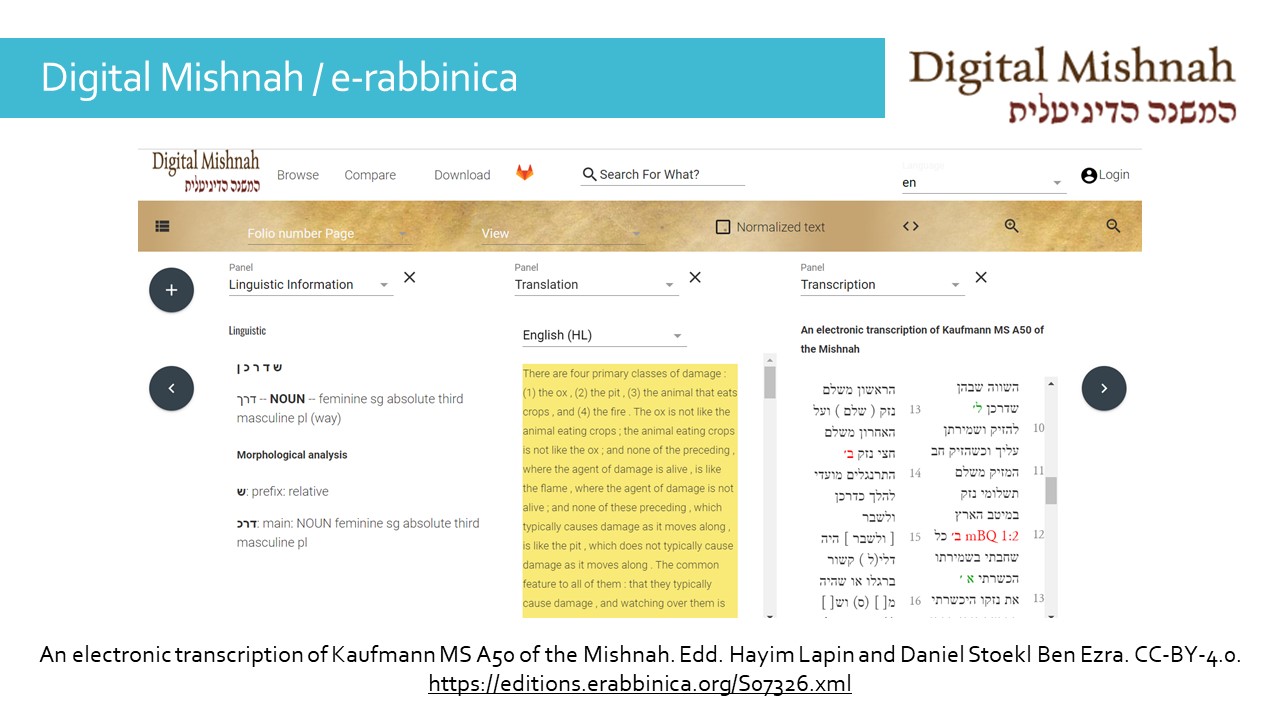
In Hebrew, we have the Digital Mishnah project: the text is accompanied here by a translation synchronised with the Hebrew, a linguistic analysis of each word. Other options include a critical apparatus, a facsimile image also synchronised with the text, and a commentary.
For Syriac there is the Digital Syriac Corpus. The Syriac Corpus is complemented by the website syriaca.org, which is the reference portal for the study of Syriac literature, history, and culture.
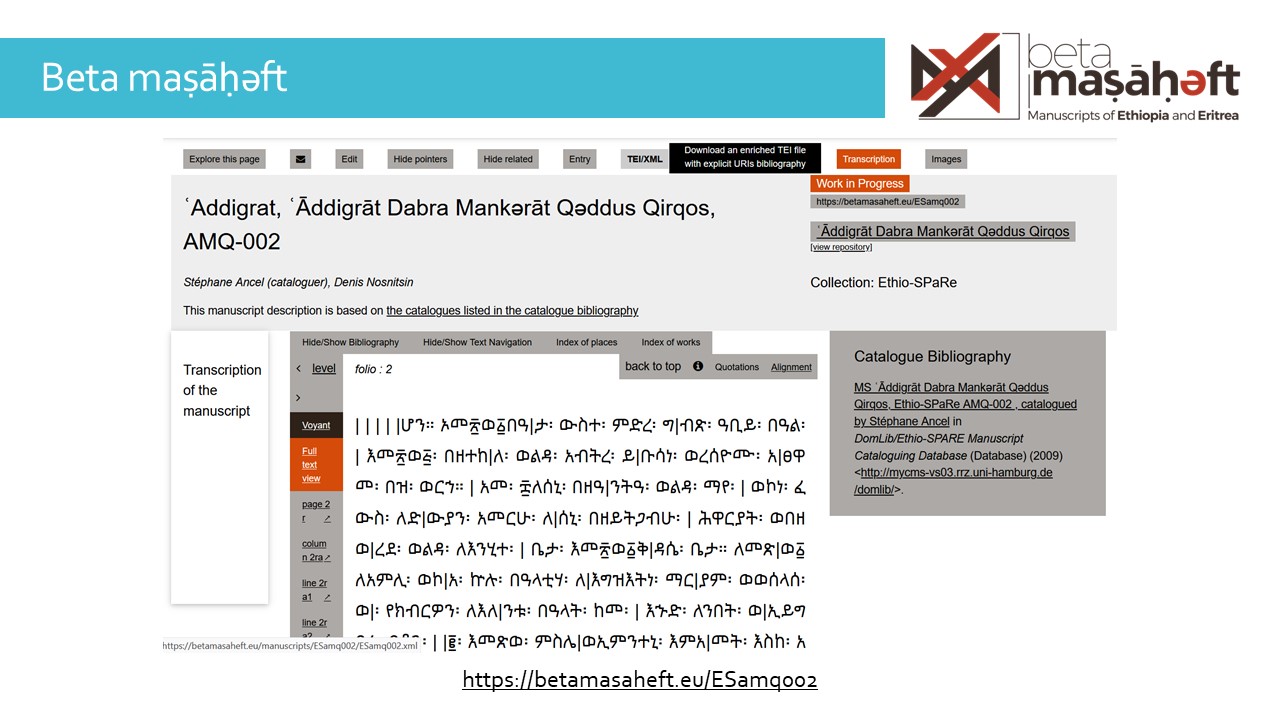
The Beta maṣāḥǝft project catalogues manuscripts from Ethiopia and Eritrea. More than two hundred manuscripts are also accompanied by a transcription.
On the Coptic Scriptorium, you can find examples in Coptic: here you have the book of Ruth, and you can choose between a complete analytical view, or the text alone for reading.
This is just a brief overview of the resources available online. For more, Jeanne-Nicole Melon Saint-Laurent (2021) offers a more detailed list of digital resources for the study of Christianity.
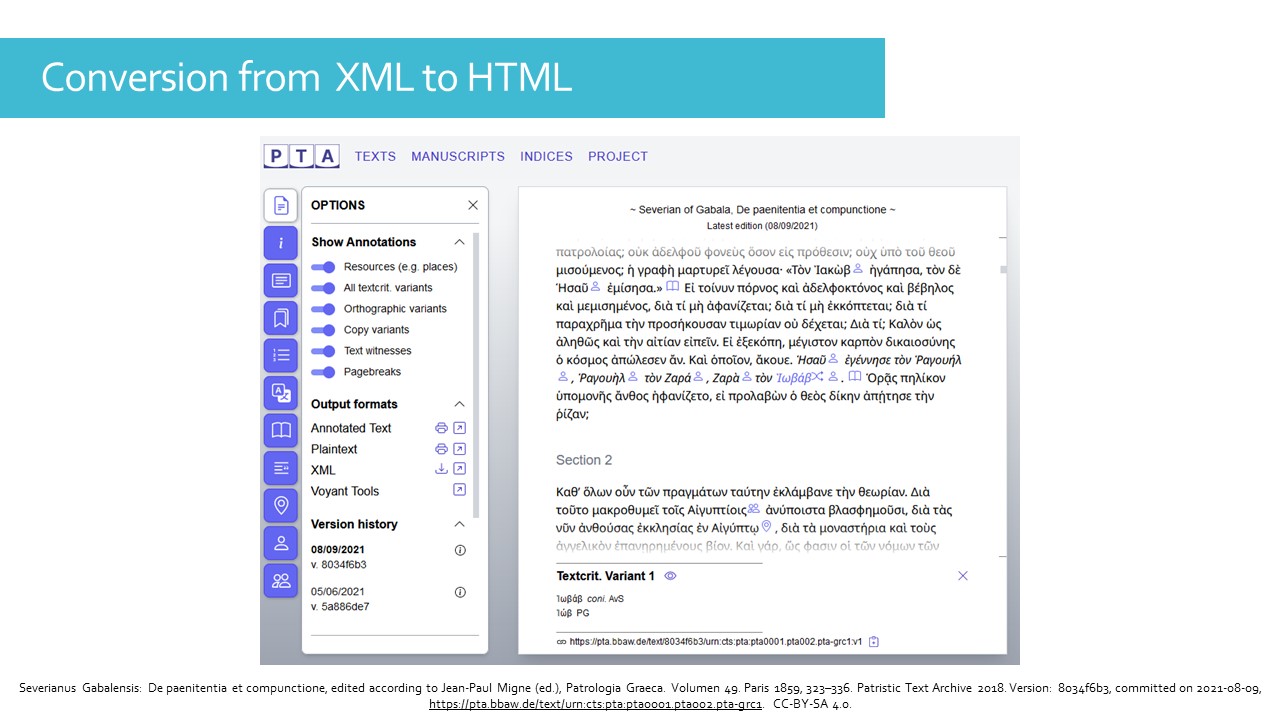
One of the advantages of encoding in XML is the ability to derive several visualisations from one single file. You can prepare a version for printing on paper, or an HTML version to make the text accessible online.
If we take the example of the PTA, the same text can be read with more or less additional information. First you have a menu of options for choosing which annotations to show in the text: names of places and people, textual variants - divided into several categories - witnesses, page breaks. The other icons on the left give access to a table of contents, a glossary, and a list of biblical and non-biblical quotations, among other things. But that is not all: the TEI format makes possible the interoperability with other tools such as Voyant Tools (in the list of options), which is a tool for corpus analysis.
If you're looking for resources to go further, once you've encoded a text, here are a few useful links for XSLT, a language that can transform XML into another format, in particular HTML. The course by Elisa Beshero-Bondar gives a fairly comprehensive overview of all these technologies and how they are combined.
Why Encoding?
The reasons why researchers adopt TEI are detailed by Lou Burnard (2015) in the introduction, and Elena Pierazzo in the TEI/XML #dariahTeach course: the possibility of separating the interpretation of the text from its visual appearance, which makes it possible to produce several different results from a single TEI file; independence from a particular technology or software, since the TEI is ultimately plain text that can be written in any editor, which also facilitates long-term conservation. The TEI is designed by and for the research community and is constantly being modified to meet their needs.
Without TEI, it is unlikely that we would have at our disposal so many fantastic resources such as those presented in this module.
To conclude, let’s read Lou Burnard on the importance of the TEI:
« [T]he TEI is part of what makes the digital humanities happen: it has become a part of the infrastructure everyone has to engage with, both technically and socially, once they start thinking about text or other forms of cultural resource in digital form. The TEI provides a toolkit with which to do that thinking, and, most importantly, it also reflects the thinking that is done». (Burnard 2015, Conclusion, §1)
Bibliography
On this last slide, you will find the references quoted in this module.




















 https://bibledhopencourseware.nakala.fr/
https://bibledhopencourseware.nakala.fr/