Bienvenue dans le troisième module de l’Opencourseware « Bible et humanités numériques » de l’Université catholique de Louvain (Belgique), créé grâce à un subside 2023 du projet Université numérique de l’UCLouvain. Ce module est une introduction à l’encodage des manuscrits avec le standard TEI/XML et en HTML pour ce qui est de la visualisation en ligne. Ce n’est pas un cours pratique d’encodage, mais plutôt un guide pour comprendre ce qu’est l’encodage, comment on procède et pourquoi on le fait.
Il existe déjà de nombreux cours, tutoriels et introductions à l’encodage, qui sont plus détaillés que ce que nous pourrions voir en quelques minutes. Le but de ce module est donc de vous orienter vers les outils et ressources qui existent déjà pour vous lancer dans l’apprentissage de l’encodage, avec des exemples tirés de la littérature biblique.
Introduction
Parmi ces ressources, j’aimerais déjà en mentionner deux qui nous serviront de référence au long de ce module :
- Digital Scholarly Editions: Manuscripts, Texts and TEI Encoding, un cours #dariahTeach créé en 2017 par Elena Pierazzo et Marjorie Burghart. Même si l’interface est en anglais, toutes les vidéos contiennent des sous-titres en français.
- Qu’est-ce que la Text Encoding Initiative ? (2015), un livre de Lou Burnard, un des fondateurs de la TEI, traduit en français par Marjorie Burghart.
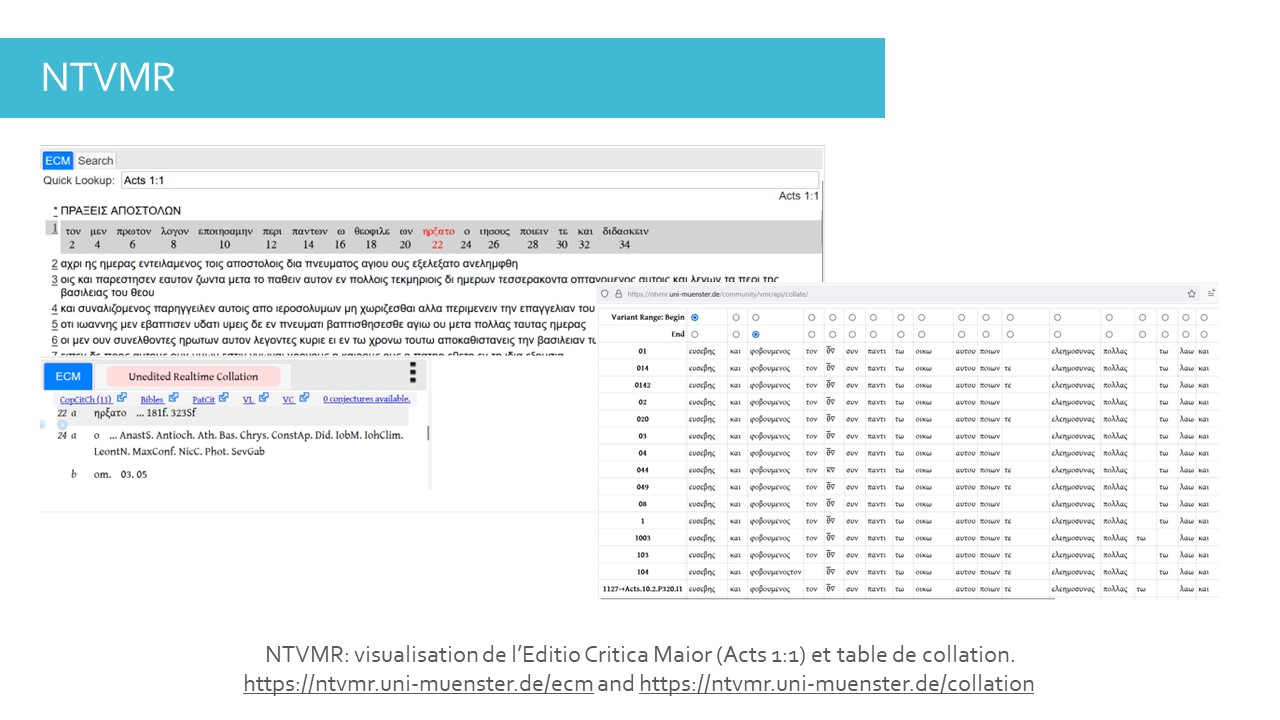
Le module précédent présentait la New Testament Virtual Manuscript Room (NTVMR) ainsi que l’Editio Critica Maior (ECM). Des outils comme la NTVMR, organisée autour des transcriptions électroniques des textes, sont considérés comme parmi les plus importants dans l’étude des manuscrits du Nouveau testament (Allen 2019).
Ces nouveaux outils qui rendent accessible à tous textes et images des manuscrits transforment le champ de recherche en études bibliques, et ont fondamentalement changé la méthodologie de l’édition des textes (Houghton 2019).
Mais ce qui rend possible de tels projets qui nécessitent la collaboration de multiple partenaires internationaux, c’est en particulier un standard commun et partagé d’encodage de textes (Houghton & Smith 2016).
Cet encodage des textes rend possible la visualisation instantanée de l’apparat critique de l’ECM, ou bien les multiples visualisations offertes comme les tables de collation.
Certains chercheurs argumentent même pour accroître la portée de l’encodage, afin de permettre une recherche plus efficace parmi d’autres aspects des manuscrits, comme leur description codicologique ou la bibliographie (Smith 2021).
L’encodage et ses balises encadrées de chevrons peuvent paraître intimidants, mais il faut savoir que c’est quelque chose que vous faites déjà tout naturellement et sans doute sans même y penser quand vous écrivez : quand vous utilisez les majuscules et les signes de ponctuation, vous encodez le début et la fin d’une phrase. Vous encodez du sens : une simple virgule peut changer complètement le sens d’une phrase. Quand vous changez la taille de la police de caractère pour mettre en évidence un titre ou un sous-titre, vous marquez une division de texte.
Cet encodage sert à faciliter grandement la lecture. Par exemple les plus anciens manuscrits sont souvent écrits en « écriture continue » (scriptio continua), en majuscule, sans ponctuation ou très peu de ponctuation. Vous avez ici un exemple manuscrit avec la transcription à côté, et un exemple de ce que cela représenterait en français avec le début de la genèse.
De la même manière, lorsque vous lisez un apparat critique, vous déchiffrez des informations encodées notamment par des caractères spéciaux : par exemple les barres verticales « encodent » la séparation entre deux entrées d’apparat ou bien entre des leçons variantes ; les marqueurs de substitutions « encodent » une variante concernant un seul (⸀) ou plusieurs mots (⸂ et ⸃), etc.
Encoder c’est intégrer dans le texte une dimension interprétative. Cela peut se faire à travers l’organisation du texte sur la page, des variations typographiques ou des signes spéciaux. Mais quand on parle d’encoder un texte, en Humanités Numériques, on utilise pour cela un langage de balisage, en particulier le XML.
La TEI, ou Text Encoding Inititative, est le standard de référence pour encoder, entre autres, les manuscrits. Ce sont des éléments XML définis par la communauté scientifique pour encoder les textes, au sens large, qui sont les sources primaires dans la recherche en Humanités. La TEI nous permet de décrire le texte, de définir ce que l’on voit sur une page de manuscrit. L’encodage en TEI apporte une dimension sémantique.
Le HTML est un autre langage de balisage qui s’utilise pour présenter du texte sur une page web. Par exemple, en HTML un mot en italique sera simplement encodé avec un élément i entre crochets, pour indiquer le fait que du texte doit être présenté en italique. Avec la TEI, au contraire, on encodera notre interprétation de ce texte comme étant à choix une emphase, un mot étranger, un titre de journal, ou bien une mise en évidence générale. Cette interprétation est indépendante de la façon dont on présente le texte sur un écran, mais essentielle pour les chercheurs qui ont besoin d’analyser leurs textes de façon pointue.
J’aimerais encore souligner que l’encodage en TEI n’est pas complètement neutre ou objectif, mais il inclut une part d’analyse. Deux chercheurs, face à une page de manuscrit, produiront deux encodages différents. Comme le note Elena Pierazzo, « l’encodage communique également la compréhension et l’interprétation, par un éditeur, des lettres sur une page ». Mais être objectif n’est pas notre but, notre but est de permettre aux autres de comprendre notre interprétation (Luizzo 2019).
Comment Encoder ?
La TEI est accompagnée de guidelines générales qui décrivent l’utilisation de chaque élément, disponibles sur le site du Consortium TEI.
Il existe certains sous-ensembles d’éléments TEI adaptés à un domaine précis de recherche. Notamment il faut mentionner ici EpiDoc, qui sont les guidelines d’encodage de documents anciens comme les papyrus ou les inscriptions épigraphiques.
Je recommande vivement de suivre le module « Manuscript Transcription » du cours #dariahTeach (vidéos no 7-14). Ce module passe en revue l’encodage de divers aspects des textes manuscrits comme les abréviations, les interventions de copiste (ajouts, suppressions, substitutions), ou les passages difficiles à lire.
Il existe des guidelines plus spécifiquement liées aux sciences bibliques. Ici je voudrais mentionner tout particulièrement deux exemples :
1. Les guidelines de l’International Greek New Testament Project (IGNTP). Ces guidelines sont influencées par EpiDoc et ont été définies pour l’encodage des manuscrits grecs du Nouveau Testament. La première version 1.1 date de février 2011, et actuellement la plus récente est la version 1.5 de 2016 par Hugh Houghton.
2. Les guidelines de Patristic Text Archive (PTA). Ces guidelines sont également inspirées d’EpiDoc, mais modifiées et enrichies, d’après le travail de Annette von Stockhausen.
Ces deux exemples vous donnent un aperçu de la façon de mettre en œuvre la TEI pour encoder des textes. On peut voir que les problématiques d’encodage entre les manuscrits grecs du Nouveau Testament et ceux des textes patristiques ont donné lieu à différents encodages, chacun valides. Par exemple la structure du texte pour les manuscrits du Nouveau testament (section 2, “division of the work”) est différente de celle des textes patristiques (section 3.4.9.1, “Encoding of the structure of the text”). Les guidelines de l’IGNTP mettent plus l’accent sur le texte et ses caractéristiques dans un manuscrit précis, alors que pour l’archive patristique, vous aurez un encodage d’un texte édité et qui met en avant aussi certains contenus comme les citations et les allusions bibliques, ou bien ce qu’on appelle les Entités Nommées, c’est-à-dire les noms de personnes et de lieux.
Pour encoder en TEI, il faut un éditeur de texte. On peut le faire en principe dans n’importe quel éditeur de texte, même le plus basique, mais certains outils peuvent grandement faciliter le processus.
L’éditeur le plus utilisés par les chercheurs pour ce qui est encodage TEI s’appelle oXygen, mais c’est un éditeur payant. Il offre des fonctionnalités particulièrement utiles comme la validation, et également un mode « auteur » qui permet de travailler sur le texte sans les balises du XML. oXygen est considéré comme le meilleur éditeur pour travailler avec la TEI, mais il existe des alternatives gratuites, comme Visual Studio Code, avec des modules complémentaires dédiés au XML.
J’aimerais aussi mentionner deux éditeurs en ligne qui vous permettent de travailler sur du texte comme dans un document Word, au lieu du XML avec ses balises.
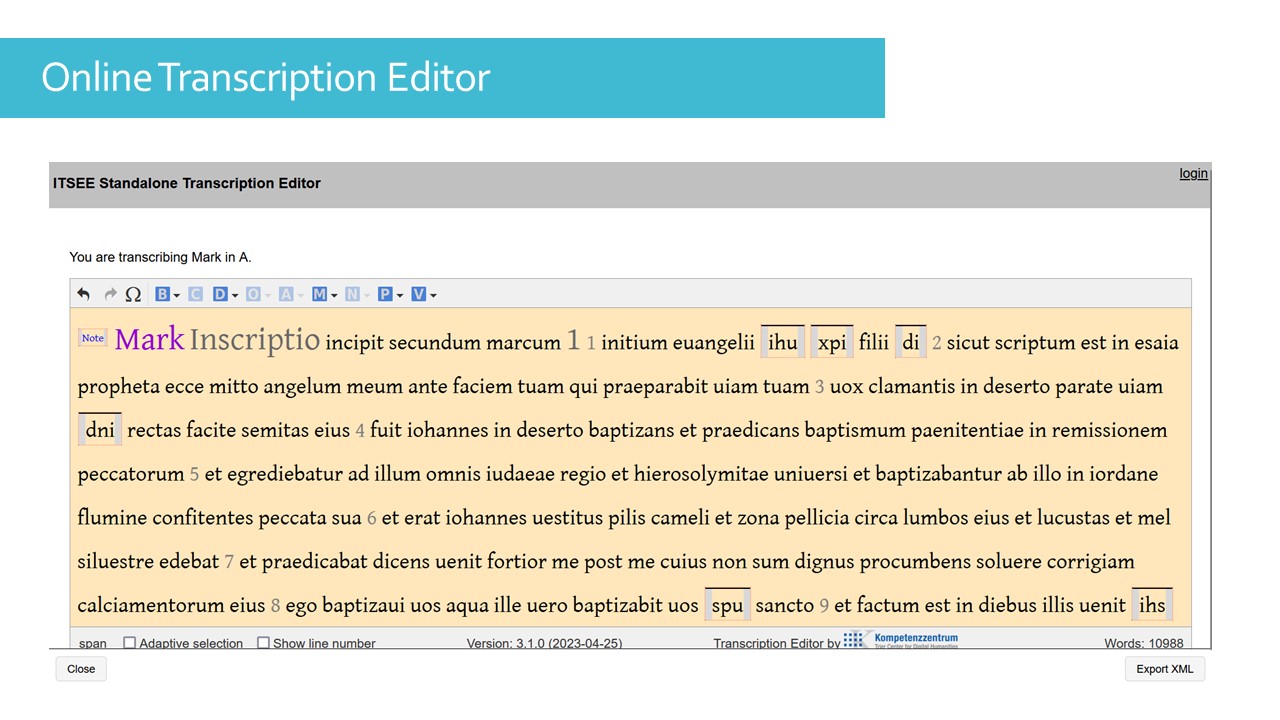
Le premier est l’Online Transcription Editor. C’est un éditeur développé dans le cadre du projet Workspace for Collaborative Editing, qui a donné lieu à l’interface de la NTVMR. La version de la NTVMR permet aux utilisateurs enregistrés notamment un export au format HTML. Cet éditeur est aussi disponible en dehors de la NTVMR. Vous pouvez choisir d’importer une transcription, ou bien de commencer à transcrire à partir d’un texte de base existant et de le modifier.
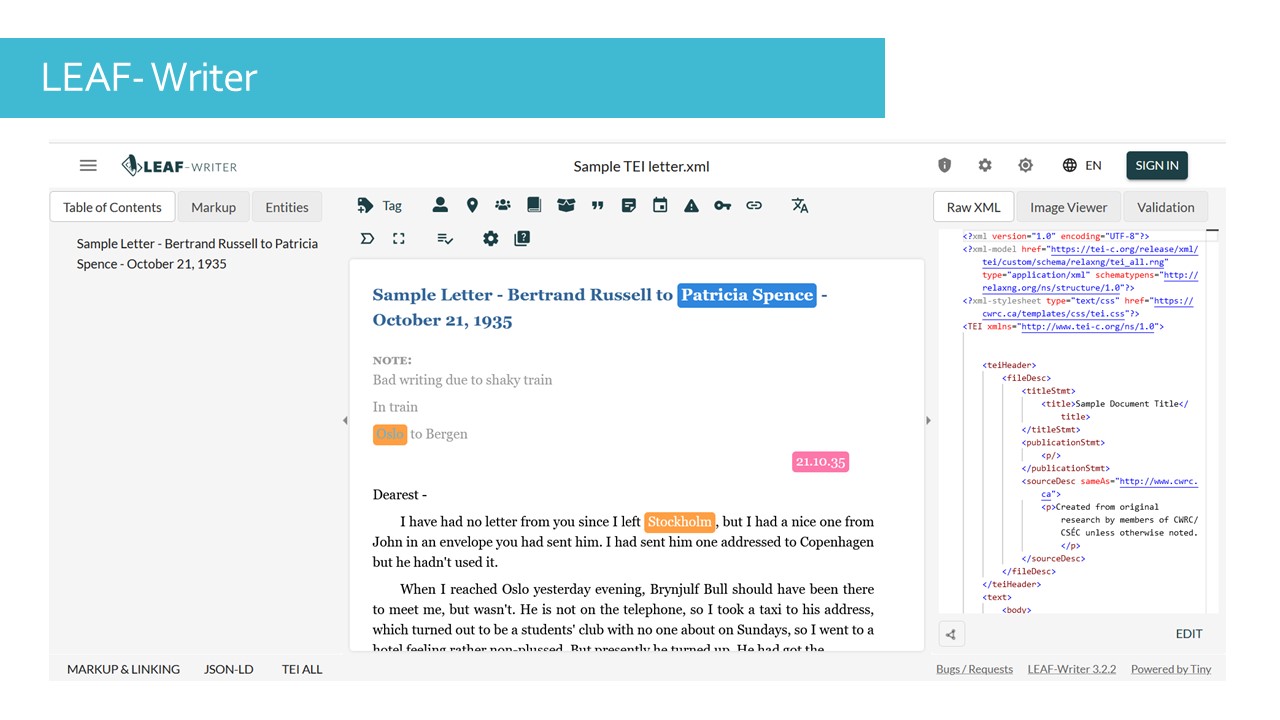
LEAF-Writer est un éditeur issu d’un projet dirigé par Susan Brown, et il est conçu spécialement pour éditer des textes en TEI, avec un public visé plus large que les chercheurs en Sciences Bibliques. Il offre plus de fonctionnalités pour travailler avec les Entités Nommées (Named Entities) et les Données Liées Ouvertes (Linked Open Data).
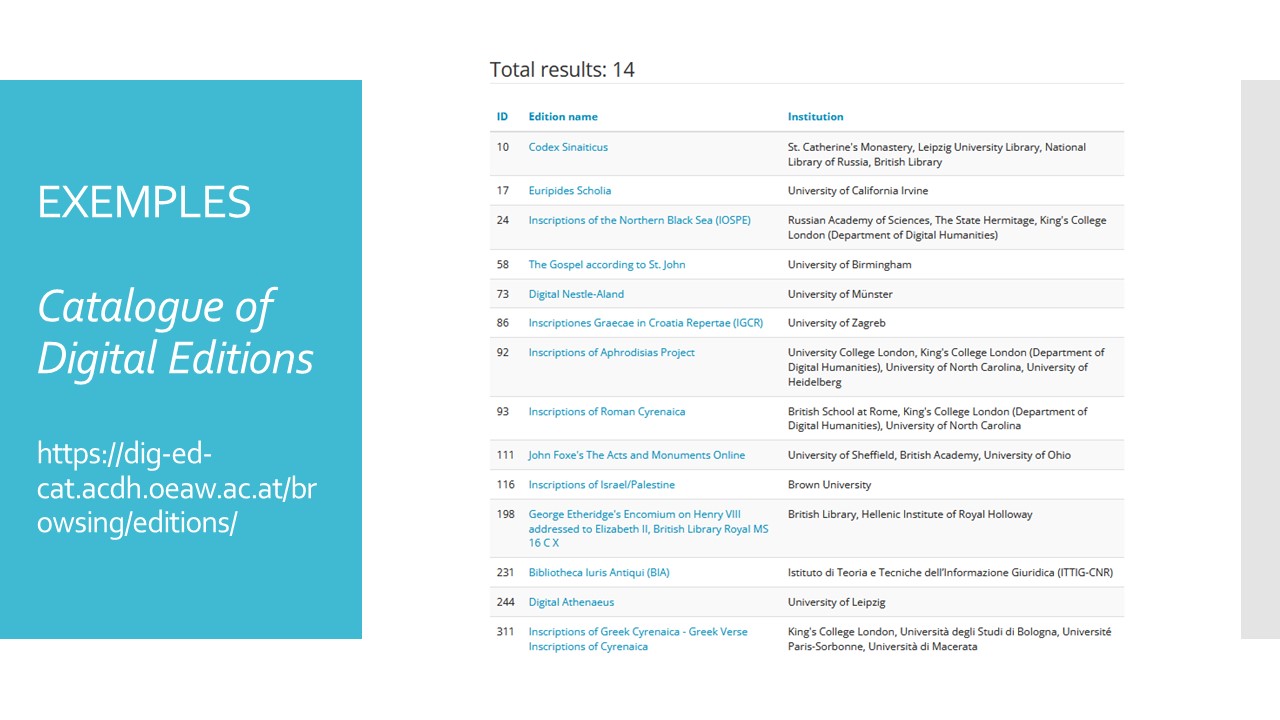
Il est toujours utile de voir des exemples d’éditions numériques en TEI pour se représenter le travail de transcription. Une bonne façon de chercher des exemples est d’utiliser le Catalogue of Digital Editions. Parmi les filtres avancés, vous pouvez sélectionner les éditions qui ont des textes encodés en TEI, par exemple ici j’ai choisi de voir les éditions de textes grecs avec un encodage TEI.
Comme il est relativement facile de trouver des exemples en grec ou latin, je voudrais aussi mentionner quelques exemples de projets qui mettent à disposition l’encodage TEI de textes en d’autres langues des manuscrits bibliques. On peut relever notamment dans la liste, au numéro 93, les Inscriptions d’Israël/Palestine, un recueil d’inscriptions épigraphiques en grec mais aussi araméen, arménien, géorgien, hébreu, phénicien, etc.
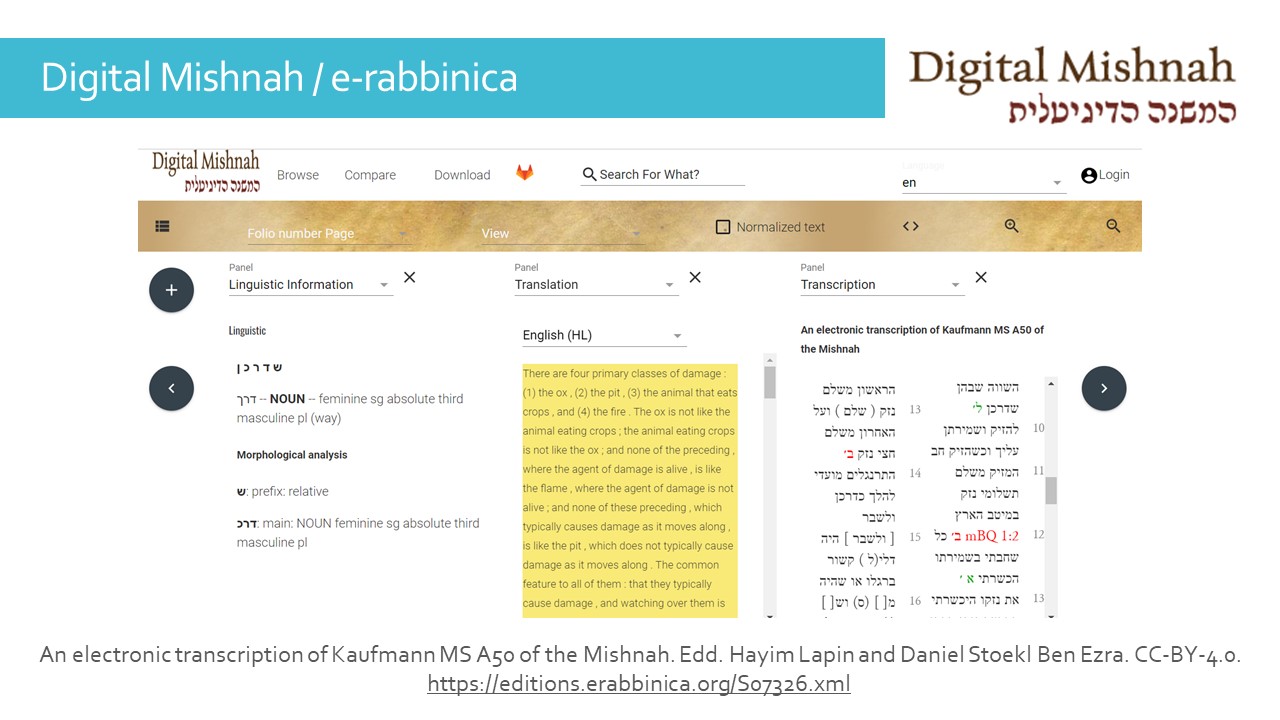
En hébreu nous avons par exemple le projet Digital Mishnah : le texte est accompagné de plusieurs outils d’aide, comme une traduction synchronisée avec l’hébreu, ou ici une analyse linguistique de chaque mot. Parmi les autres options disponibles il y a un apparat critique, une image également synchronisée avec le texte, et un commentaire.
Pour ce qui est du Syriac, vous avez par exemple le Digital Syriac Corpus. Le corpus syriaque est complété par le site syriaca.org, le portail de référence pour l’étude de la littérature, l’histoire et la culture syriaque.
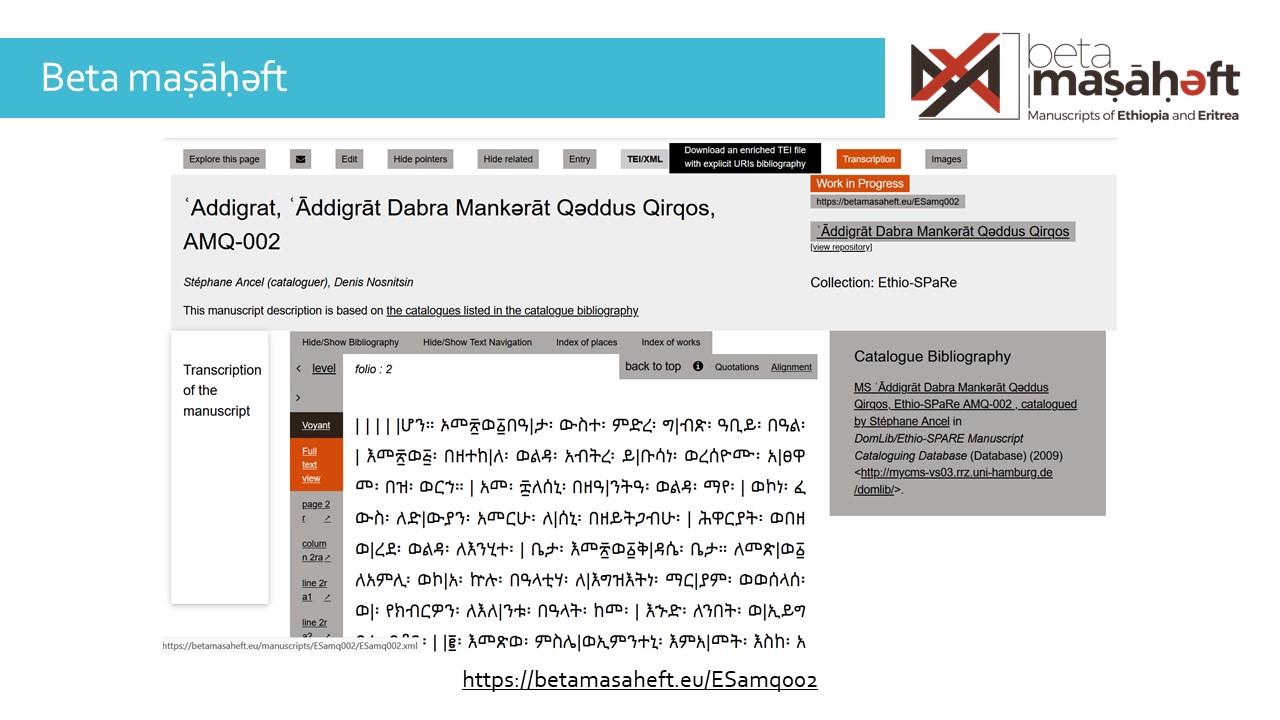
Le projet Beta maṣāḥǝft recense les manuscrits d’Ethiopie et Erythrée. Un peu plus de deux cents manuscrits sont accompagnés d’une transcription.
Sur le site du Coptic Scriptorium, vous pouvez trouver des exemples en copte : vous avez le choix entre une visualisation analytique complète, ou bien le texte seul pour lecture.
Ce n’est qu’un bref aperçu des ressources qui se trouvent en ligne. Pour plus d’outils, Jeanne-Nicole Melon Saint-Laurent (2021) propose un plus large panorama des ressources numériques pour l’étude du christianisme.
L’un des avantages de l’encodage en XML, c’est la possibilité de dériver plusieurs visualisations à partir d’une ressource. On peut préparer une version statique, prête à être imprimée sur papier, ou bien une version HTML interactive accessible en ligne.
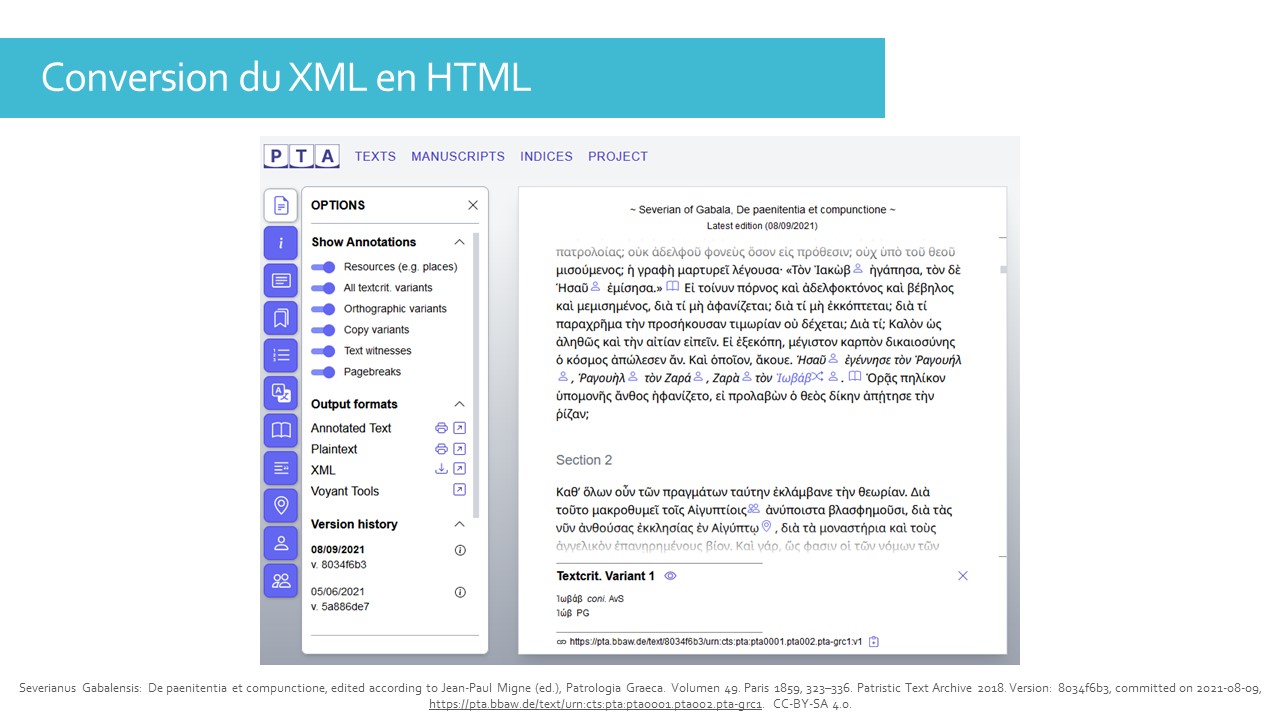
Si l’on reprend un exemple de l’archive patristiques, le même texte peut être lu avec plus ou moins d’informations complémentaires. Vous avez en premier lieu un menu d’options pour choisir les annotations à montrer dans le texte : les noms de lieux et de personnes, les variantes textuelles - divisées en plusieurs catégories - les témoins, les sauts de page. Les autres icônes sur la gauche donnent accès entre autres à une table des matières, un lexique, la liste des citations bibliques, et non bibliques. Mais ce n’est pas tout : grâce au format TEI, cela rend possible l’interopérabilité avec d’autres outils comme Voyant Tools (dans la liste des options), qui permet d'analyser un corpus textuel.
Si vous cherchez des ressources pour aller plus loin une fois que vous avez encodé un texte, voici quelques pistes : le XSLT est un langage qui permet de transformer le XML en un autre format, comme le HTML. Notamment, le cours par Elisa Beshero-Bondar donne un aperçu assez complet de ces technologies.
Pourquoi encoder ?
Les raisons qui poussent les chercheurs à adopter la TEI sont détaillées par Lou Burnard (2015) en introduction, et Elena Pierazzo dans le cours #dariahTeach : la possibilité de séparer l’interprétation du texte et son apparence visuelle ce qui par conséquent permet à partir d’un seul contenu en TEI de produire plusieurs résultats ; l’indépendance à une technologie ou un logiciel particulier puisque la TEI est finalement du texte qui peut s’écrire dans n’importe quel éditeur ce qui facilite aussi la conservation sur le long terme. La TEI est conçue par et pour la communauté de chercheurs, et elle est constamment modifiée pour répondre à leurs besoins.
Sans la TEI, il est peu probable que nous ayons à notre disposition autant de fantastiques ressources comme celles présentées dans ce module.
Pour conclure, citons encore Lou Burnard sur l’importance de la TEI :
La TEI fait partie de ce qui rend possible les humanités numériques : elle est devenue une partie intégrante de l’infrastructure à laquelle tout le monde a affaire, techniquement et socialement, dès que l’on commence à réfléchir sur le texte ou sur d’autres formes de ressources culturelles sous forme numérique. La TEI propose un ensemble d’outils pour mener cette réflexion, et, plus important encore, elle reflète aussi la réflexion en question, à la fois dans ses préoccupations et ses bizarreries occasionnelles. (Burnard 2015, trad. Marjorie Burghart, conclusion, §1).
Bibliographie
Sur cette slide vous trouverez les références citées dans ce module.




















 https://bibledhopencourseware.nakala.fr/
https://bibledhopencourseware.nakala.fr/