My name is Vincent Mooser, I’m responsible for the Laboratory department at CHUV, and I’m also vice-dean in charge of clinical research at the University of Lausanne medical school.
What I would like to talk about today is the Lausanne Institutional Biobank.
The content of this presentation is shown on this slide : First, I will illustrate what is the opportunity, essentialy the conversion of present medicine into the future of medicine.
I will then go into what are the challenges that we are facing to realize this potential ;
Third, I will describe an initiative that we have already launched here in Lausanne called « CoLaus project », it demonstrates how we can use this type of initiative to support drug discovery ;
That will lead to the fourth part of my presentation, the biobank, and parallel initiatives, essentially an integrated platform to support biomedical sciences.
And I will finish up with some conclusions.
So now, I will move into the first part of this presentation: the opportunity.
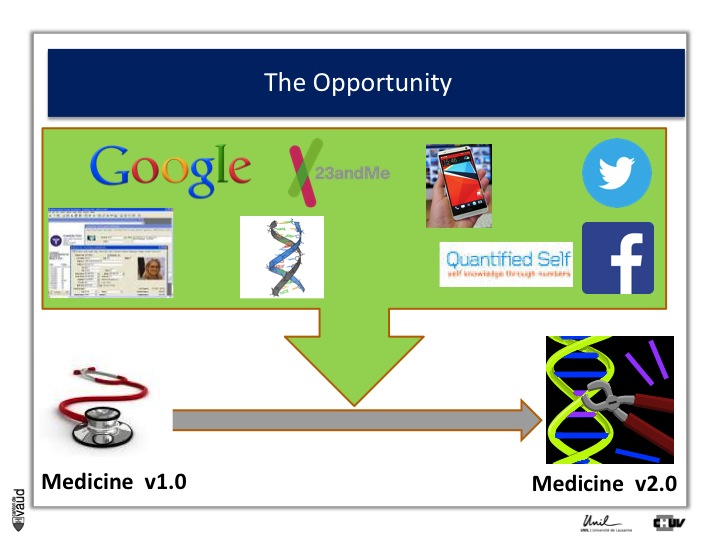
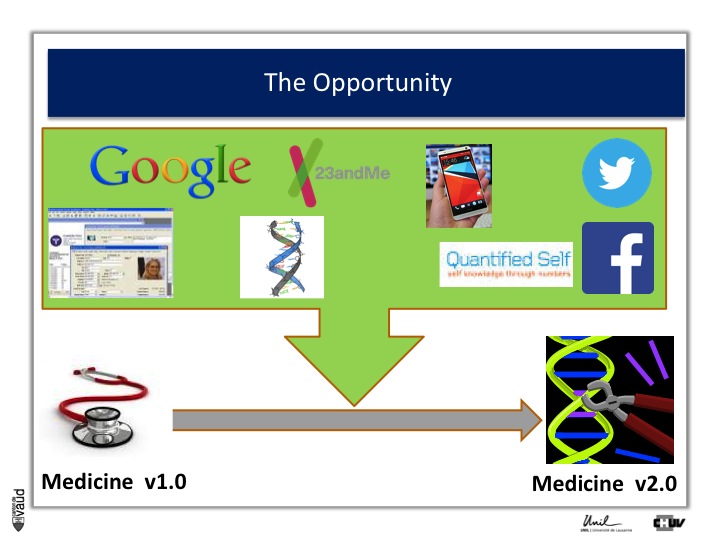
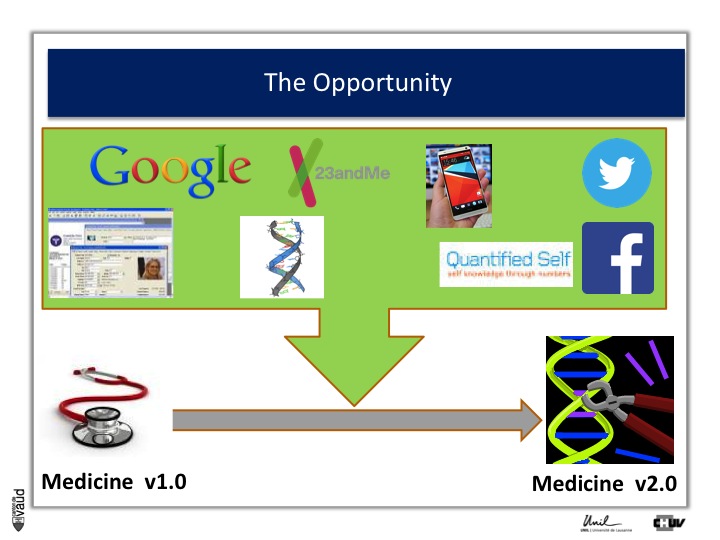
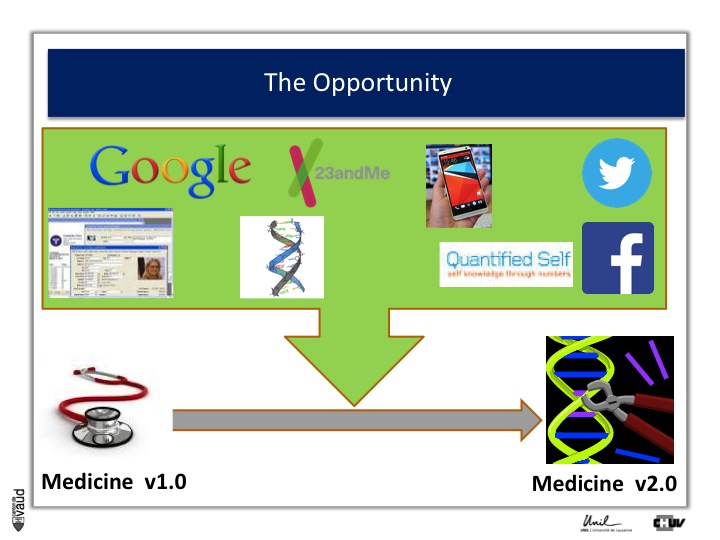
The opportunity: from Medicine v1.0 to Medicine 2.0
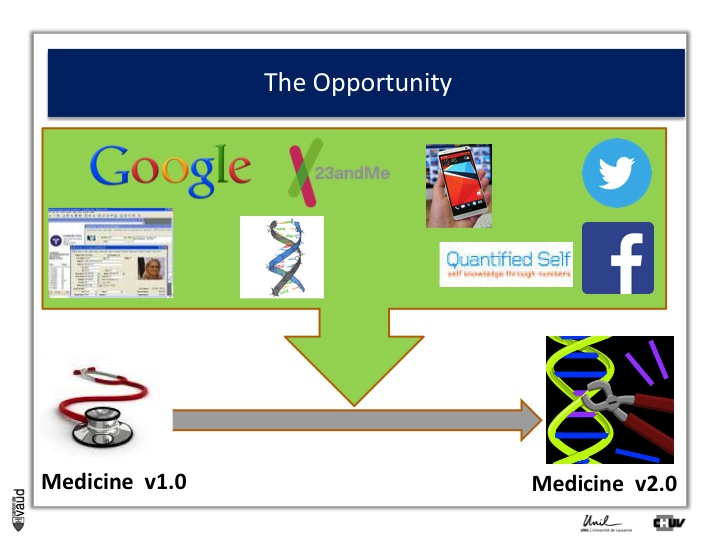
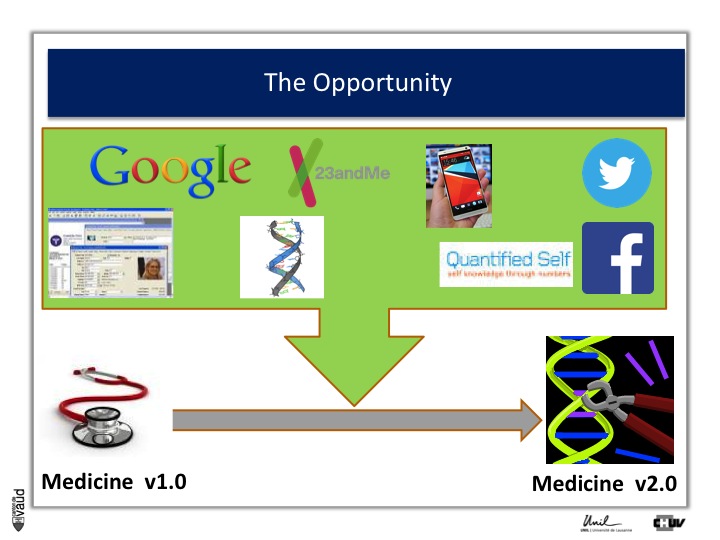
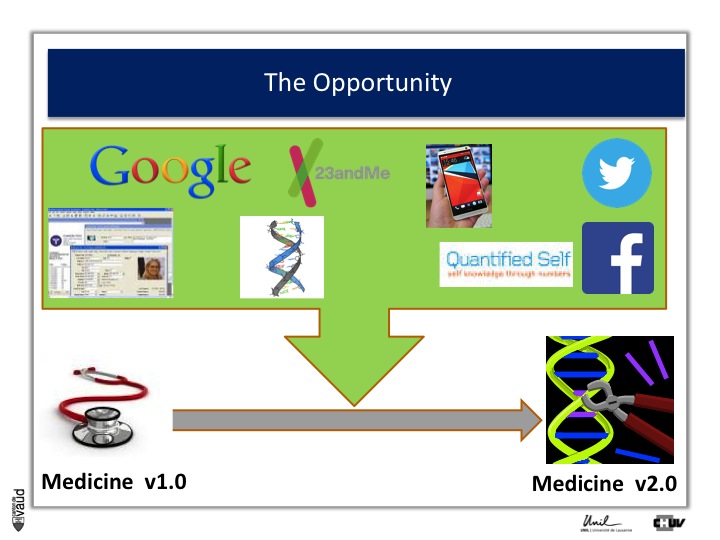
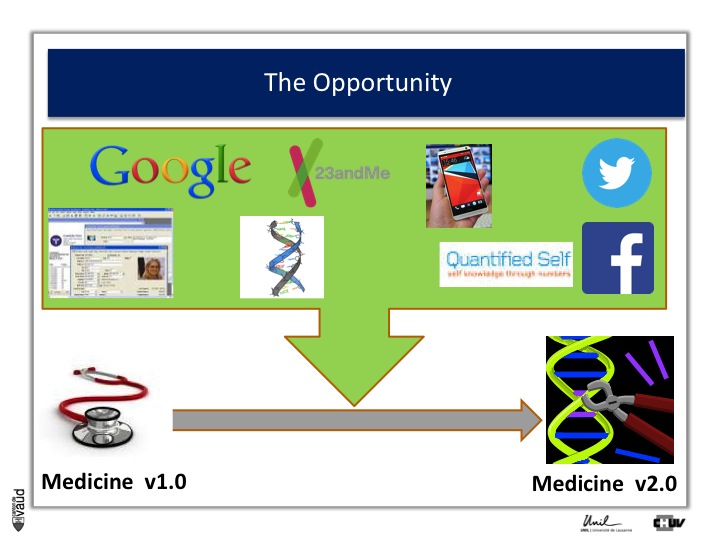
The opportunity is described in more details in this slide. Essentially, what it shows is that with IT developments and genomic developments, we are attending a dramatic change in the way medicine will be practiced.
There is no doubt that medicine will be changed because of electronic medical records (which is shown on the upper part of the Figure on the left) ;
Essentially now in most hospitals, like ours here in Lausanne, all the medical records are kept electronically.
There are now some research engines, like Google, there is this genomic revolution (I will describe that in more details in a few seconds), there are direct-to-consumer genetics, like 23andMe initiatives ;
There is the Quantified Self also, which is this trend whereby now people can monitor a variety different parametres, using biosensors to monitor their glucose or blood pressure or heart rate continuously ;
And of course, there are social networks like Twitter and Facebook, which contribute as well to generate a lot of data, which is relevant from the biomedical perspective.
And if we can integrate this data, we can really be in a good position to make big changes in the way we are practicing medicine : this is what could be called « medicine 2.0 ».
What is medicine 2.0 ? Medicine 2.0 uses in particular our genomic make-up to make decisions.
And shown on this slide here is a paper where we showed that indeed, each of us is carrying rare mutations in our genome which have the potential to affect the quantity or the quality of the gene product, and as such predisposes us to react in a particular way if we are exposed to an environment like a drug, or a toxic, and we are predisposed to specific diseases.
So the question is how we can capitalize on this variation to facilitate the medicine and improve its efficiency.
Actually, this is becoming a reality ; now there are some machines which are capable of sequencing for 3 billion base pairs of our individual genome, for less than 1000 dollars in just a few hours.
This, as you can imagine, generates enormous IT challenges as well, which we can discuss also later.
Leroy Hood talks about the four « P » of the future of medicine.
And these four « P » are personalized medicine, predictive medicine, preventative medicine, and participative. And the four aspects of this future of medicine are closely interconnected.
I will take now examples for each of these P‘s to illustrate what we are talking about.
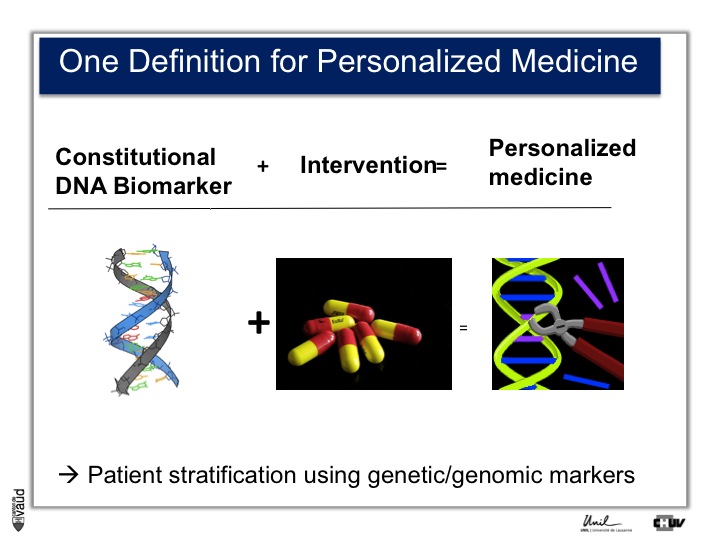
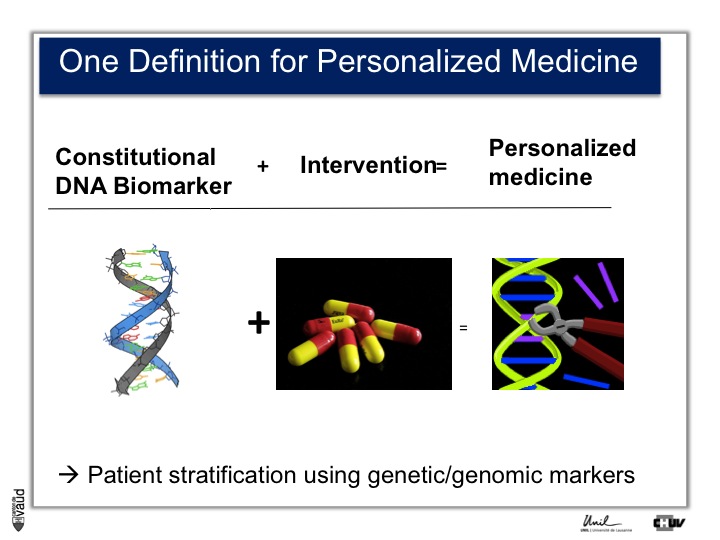
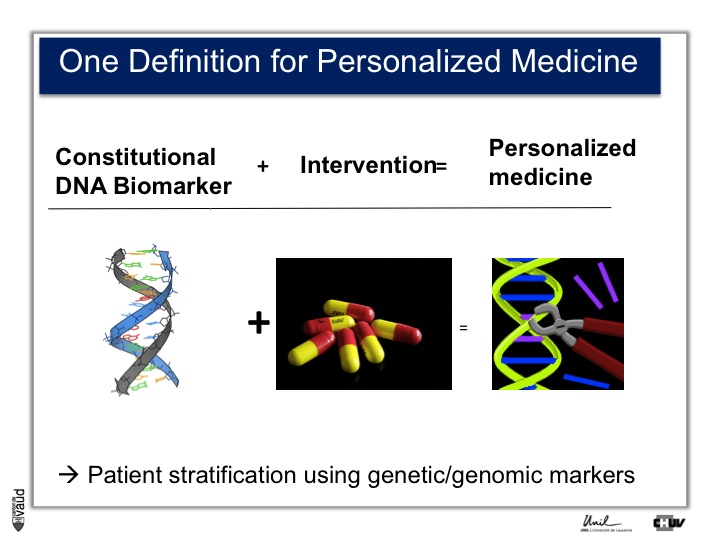
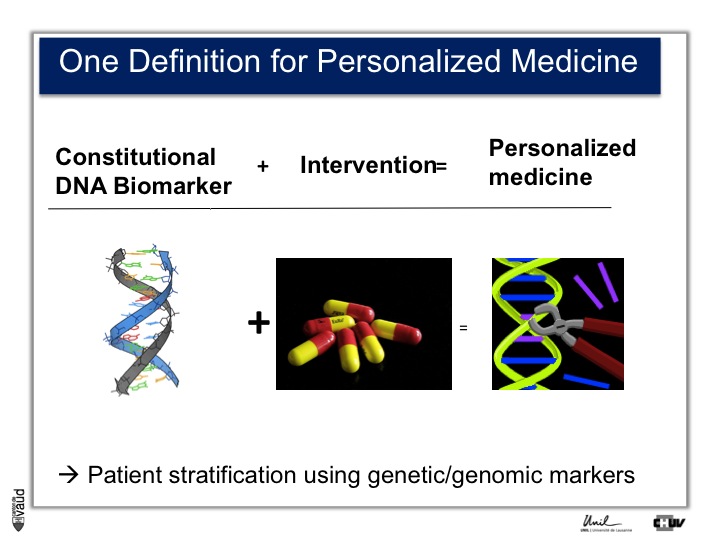
First, personalized medicine. There are a variety of definitions for personalized medicine. If you’re going to Google or PubMed and you are looking for « personalized medicine », you’ll see more than 15000 papers or hits.
Even if you type « personalized medicine review », you’ll get at least 5000 hits. So, this is here a very trendy word, and one simple definition could be the use of a DNA biomarker plus intervention, which essentialy means that we can stratify the patients using genetic or genomic markers.
I think it’s fair to say that personalized medicine presently has really made an impact in oncology where somatic, that means tissue DNA biomarkers, are used to tailor the treatment to a particular genetic make-up of the tumor.
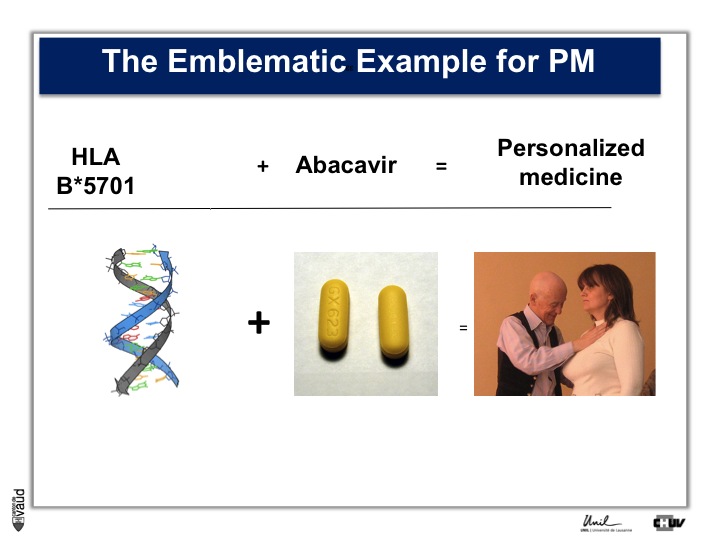
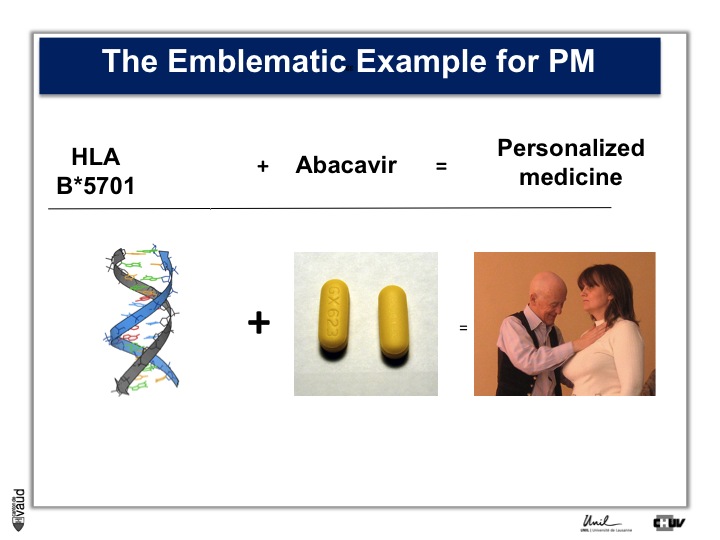
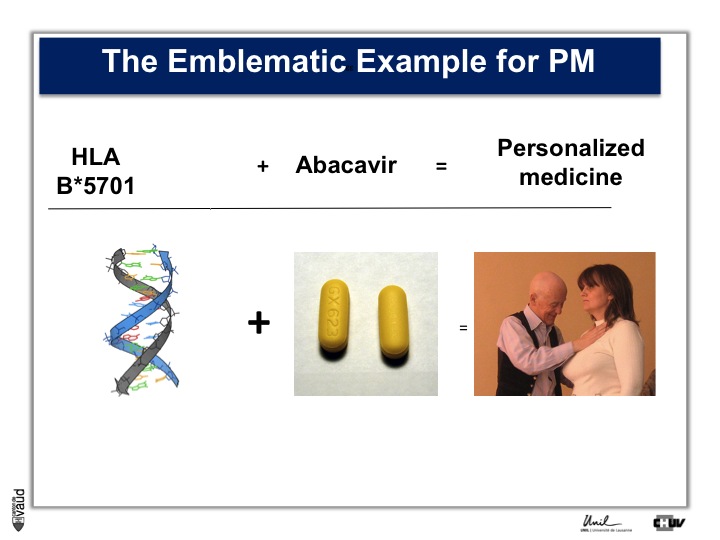
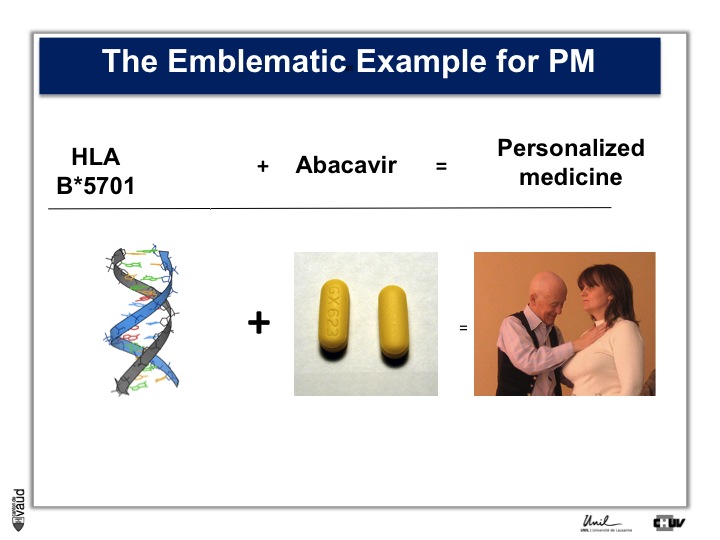
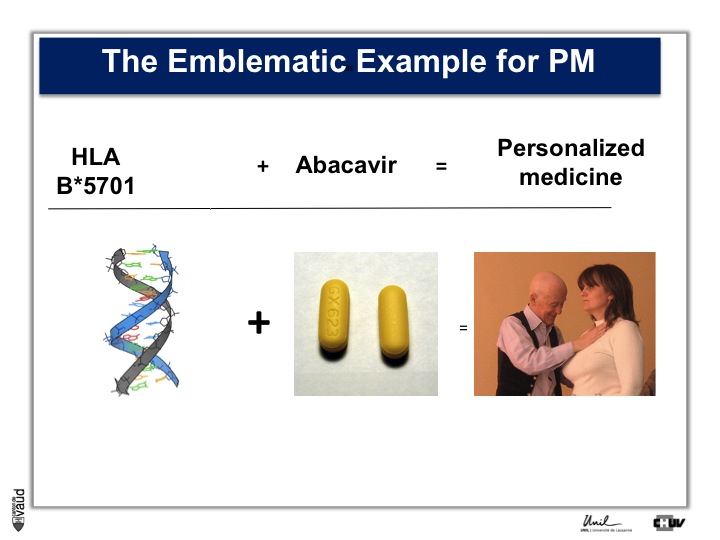
In terms of constitutional, that means heritable DNA, there are not that many examples, and probably the most emblematic one is Abacavir.
Abacavir is an anti-HIV drug which, in 3% of the patients, elicits a hypersensitivity reaction which can be lethal.
Back in 2002, there was a marker in the constitutional DNA, in the HLA region on chromosome 6, which was shown to be associated with this reaction.
Now, people are testing HIV patients before they are prescribed Abacavir and doctors look if they are carriers of this particular marker.
If they do carry this marker, then doctors to not prescribe this drug, and since then, the side effect which you can see on the picture on the right, has essentially disappeared.
This is an example of personalized medicine.
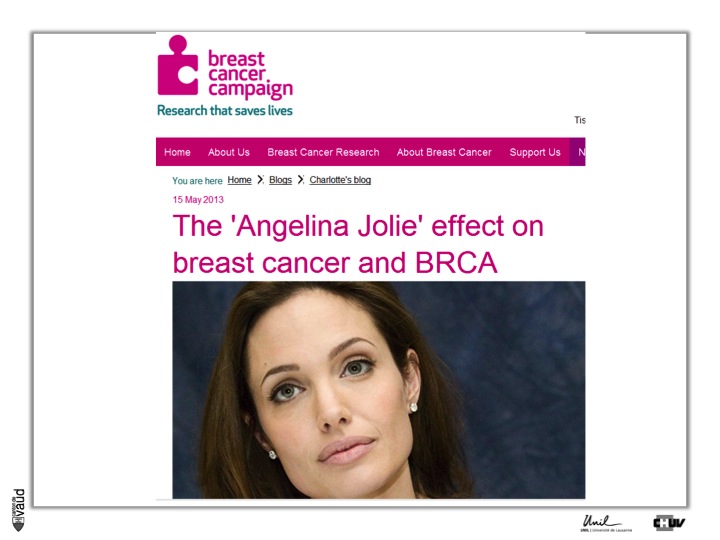
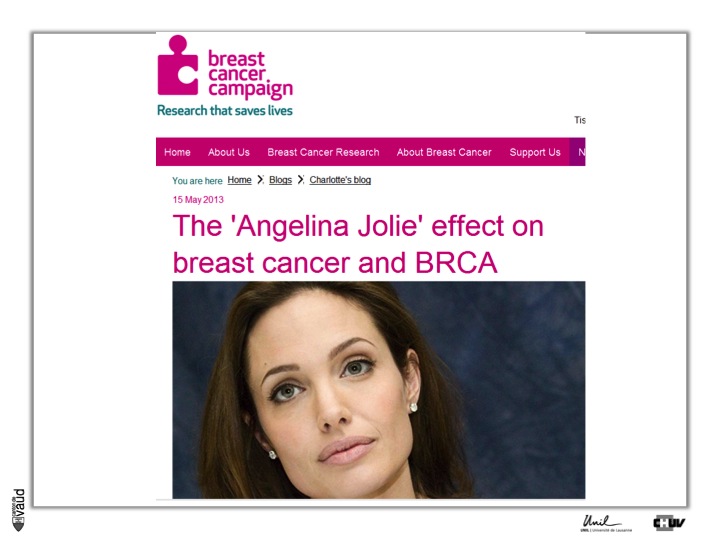
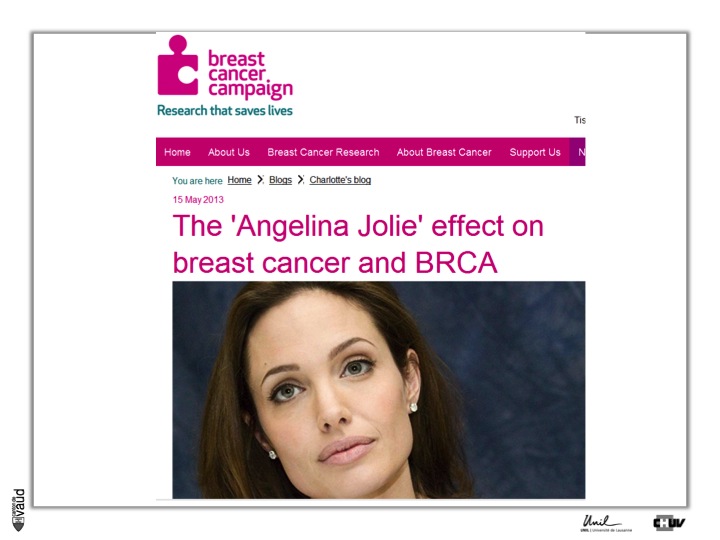
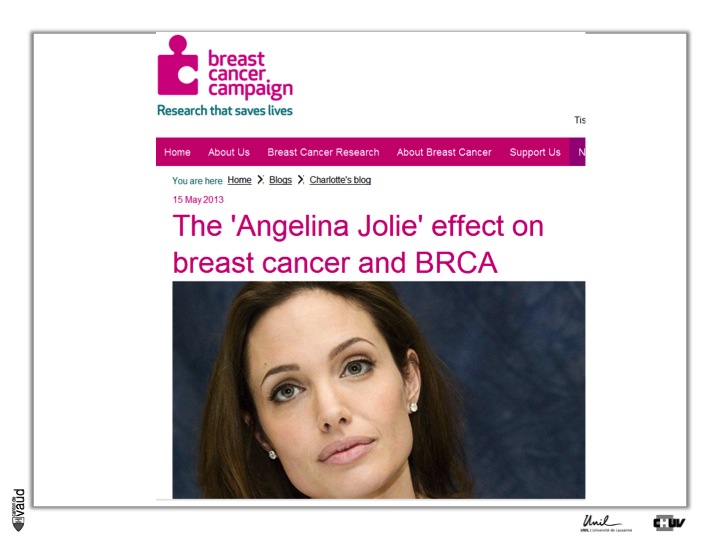
Now, if we are looking at examples for preventive and predictive medicine, we can certainly here mention the case of Angelina Jolie.
As you know, Mrs Jolie is carrying a tumor-predisposing mutation within the gene called BRCA1. She was tested for this gene and was shown to carry this mutation, so she has a high genetic susceptibility to develop breast and ovary cancer.
This is predictive medicine. Essentialy, a genetic marker with a certain probability (we talk about penetrance) to develop this disease over her lifetime.
And what she did is deciding to have some preventive measures, in the sense that she decided to have her breasts removed to avoid the risk of developing breast cancer.
In terms of participative, now, I’m taking an example here which is a direct-to-consumer genetics private initiative called 23andMe.
What this company in California offers is, provided you pay 99 dollars plus 9 dollars a month,
they give you information pertaining to your genome, essentially they do what is called a genome wide association study, where they analyse a couple of millions of variants in the genome and tell you whether you are predisposed to a particular disease or not.
I shall mention here that this part of their business has now been stopped and they are now much more devoted because of some problems with the FDA to sort of « funny » genetics, that means mostly genealogy but less so about health-related genetics.
That leads me to the second part of this presentation ; the challenges that we are now facing to realize this potential of more personalized, predictive, preventive and participative medicine.
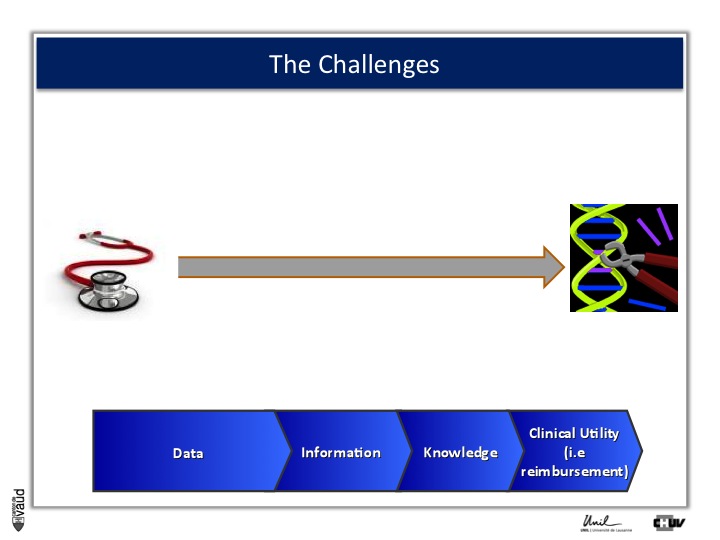
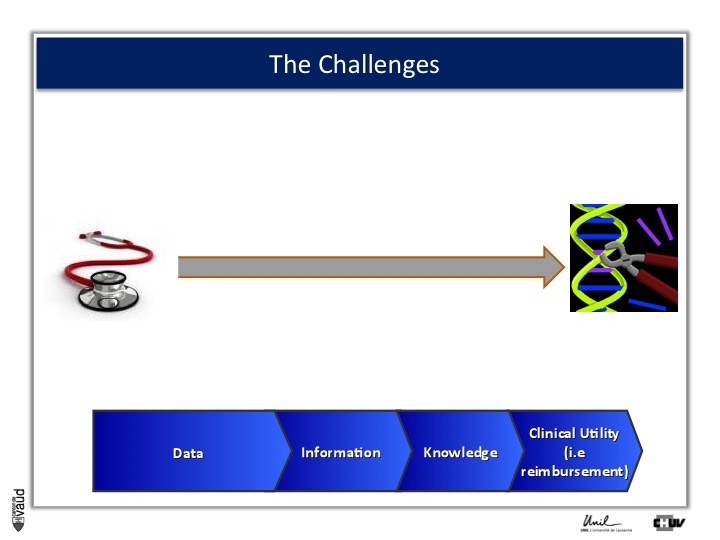
The challenges: how to realize this potential
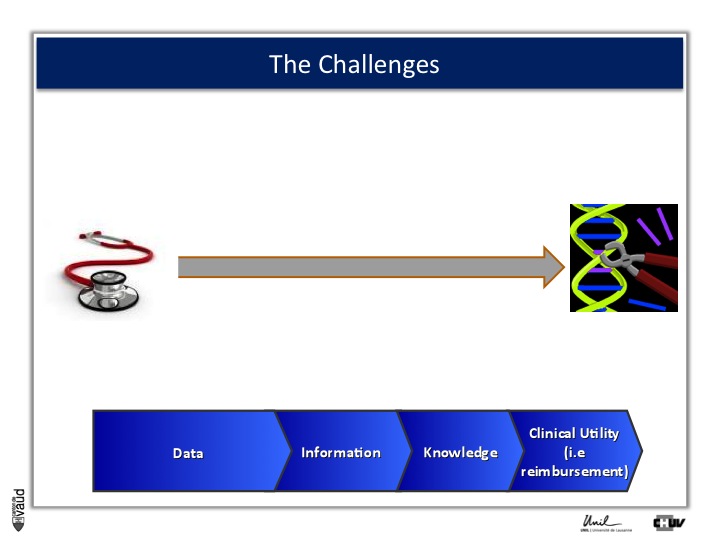
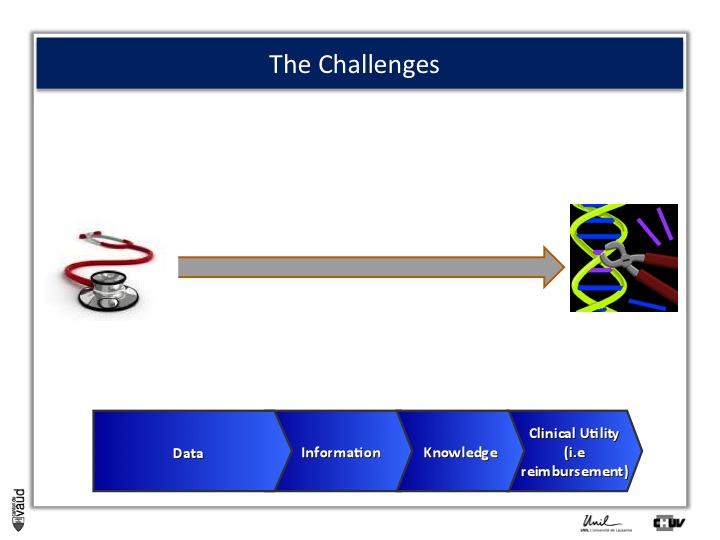
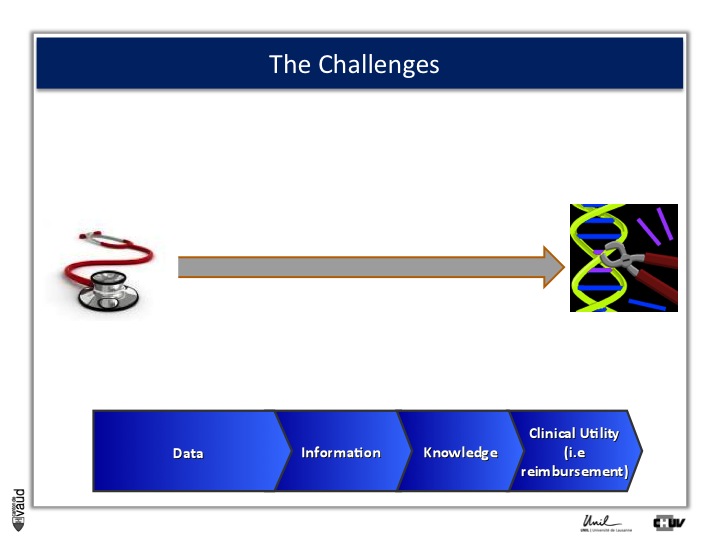
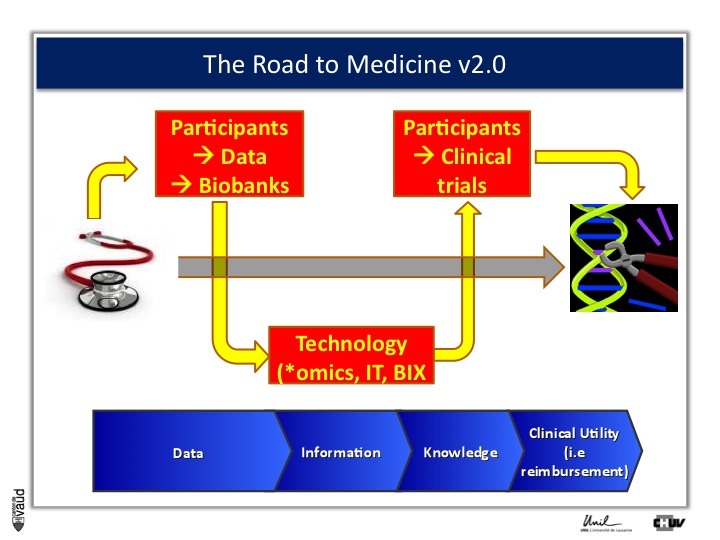
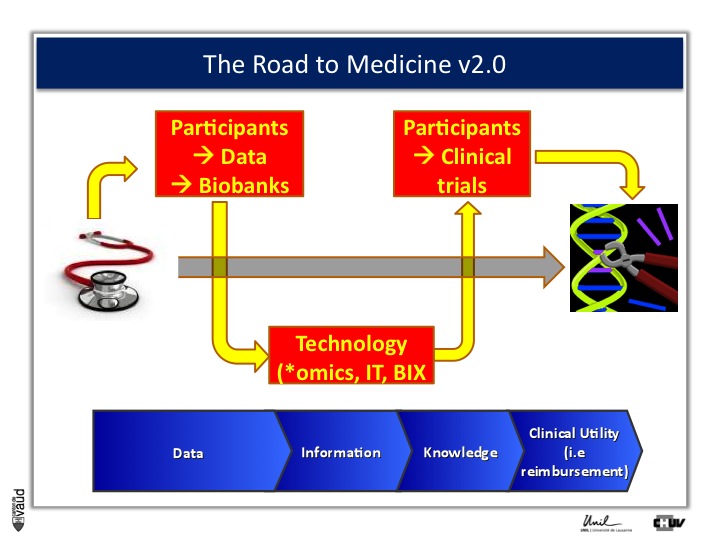
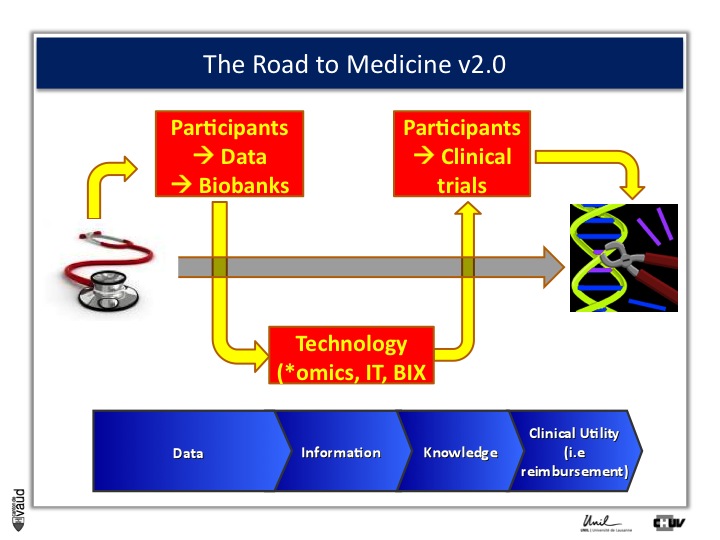
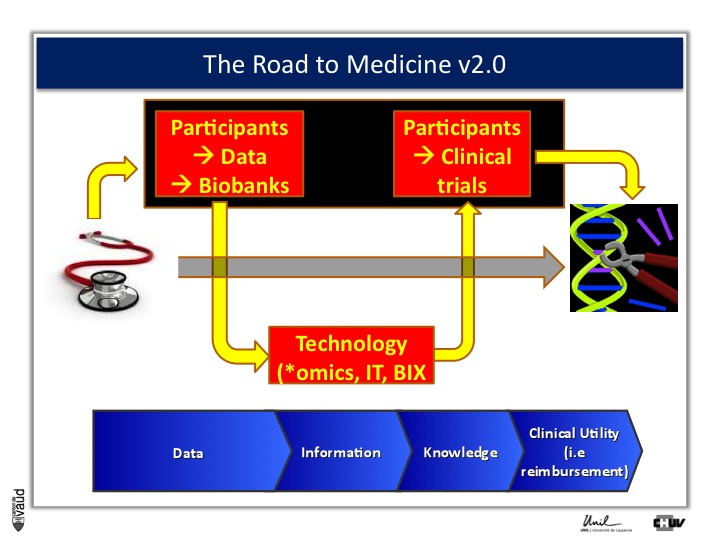
And this challenge is illustrated on this Figure.
The big challenge is not to generate data ; because now, it’s very cheap to generate data – again, this data could be biomedical data, data generated using sequencing of the genome, but also electronic medical records, twitters, and so forth.
The big challenge is to convert this data into information.
Ultimately to knowledge ; but knowledge is not enough, and I willl give you an example later.
Knowledge, here in terms of medicine 2.0, is only useful when you can demonstrate its clinical utility, which also means reimbursement if we are talking about drugs or biomarkers.
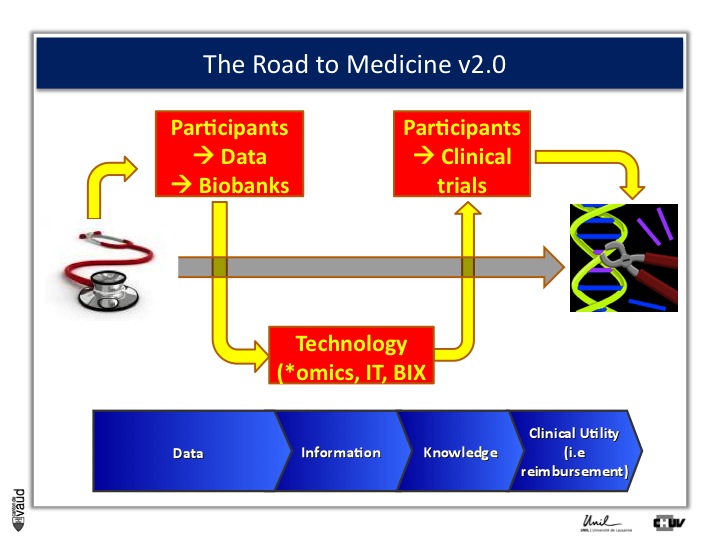
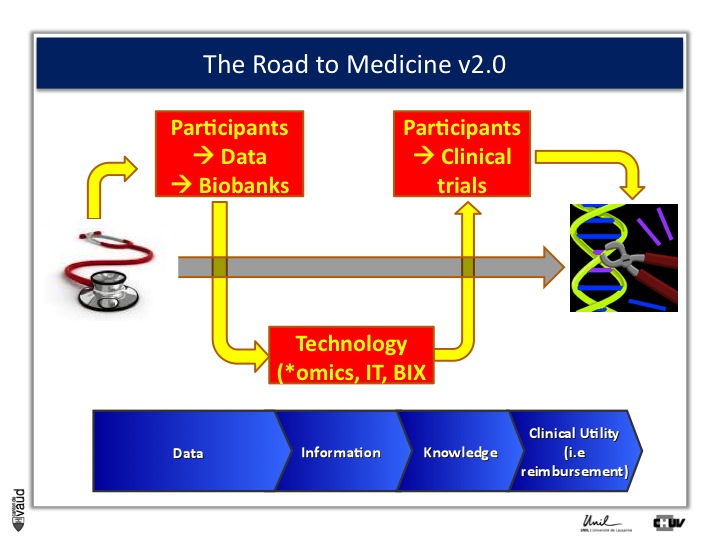
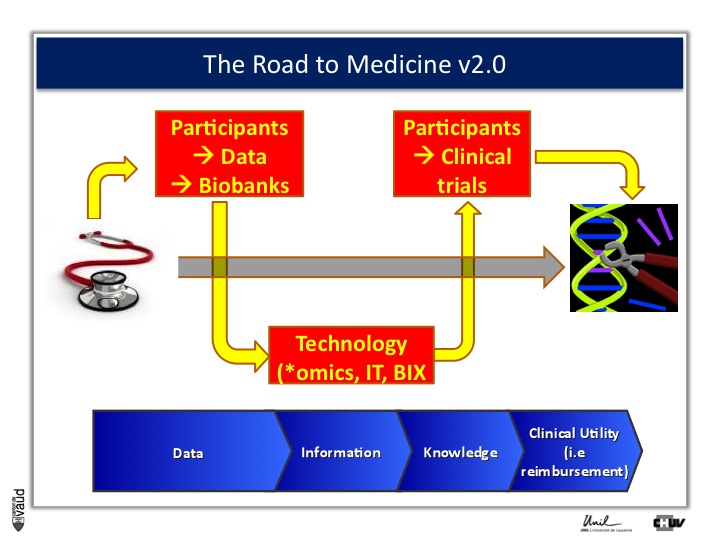
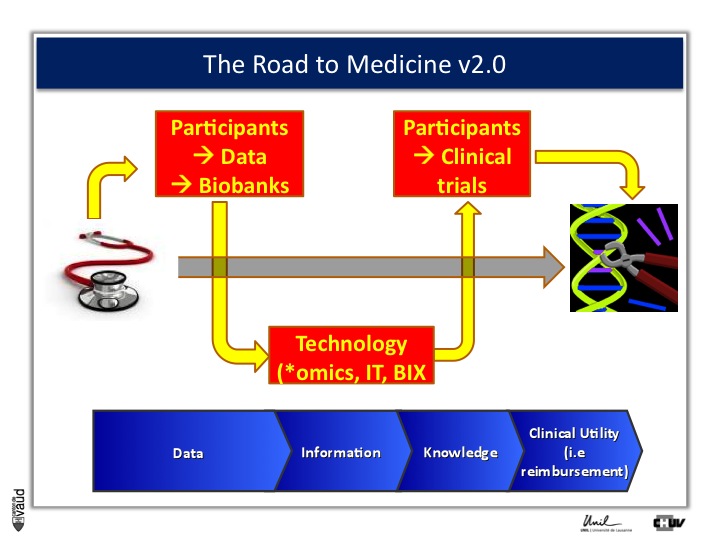
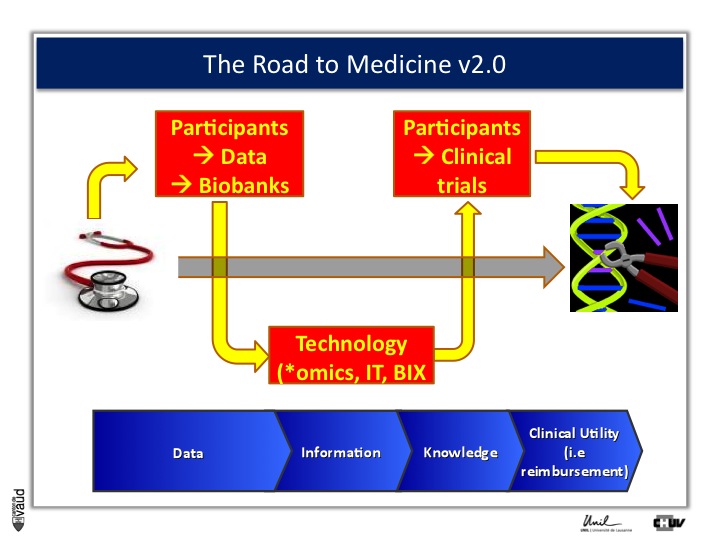
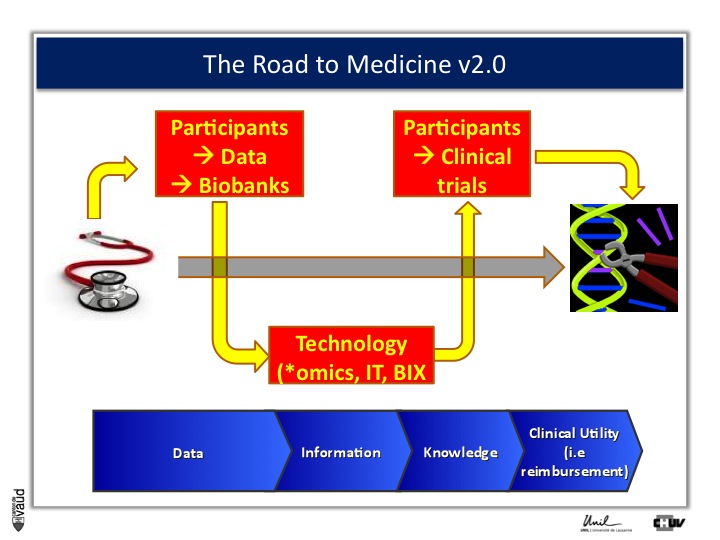
And one way to move from data down this road to clinical utility is illustrated on this slide.
The idea here is that, if we want to make an impact on medicine 2.0, we need to have access to high quality data from large number of participants.
We also need to have access to samples from these individuals ; i.e. collect these samples and store them into a biobank.
The biobank is a structured, organized repository for biomedical samples which will be used for research.
These samples will be analyzed, using various technologies : we talk about genomics if we want to sequence the genome like mentioned before ;
We talk about metabolics, if we want to analyse the profile of small molecules in a particular fluid ;
We talk about proteomics if we’re looking at proteins in these fluids.
All these « omic » technologies generate big amounts of data and require access to a robust IT technology platform, but also bioinformatics, or BIX here, to make sense out of this wealth of data.
If we are taking the case of Abacavir that I was showing before, it essentially took five years to go from the discovery of this association between HLAB57O1 and this hyper-sensivity reaction to clinical utility, that means to show, that if we have a test, you can prevent the occurrence of the side effects.
And that requires going back to participants, going back to patients, and running clinical trials.
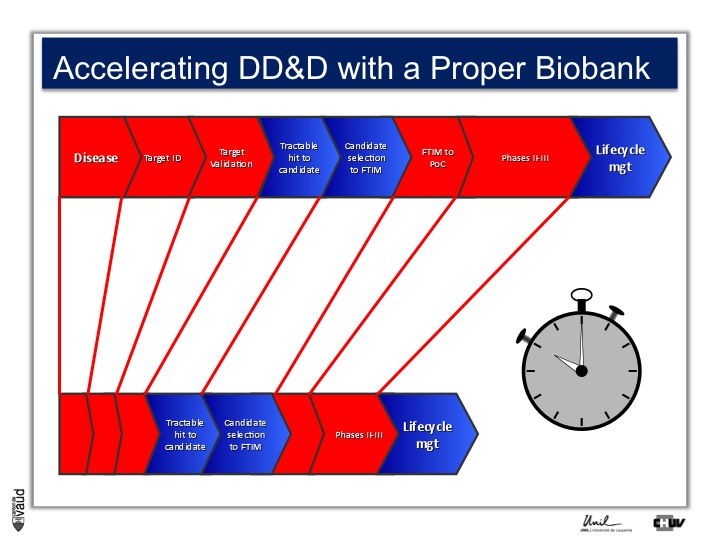
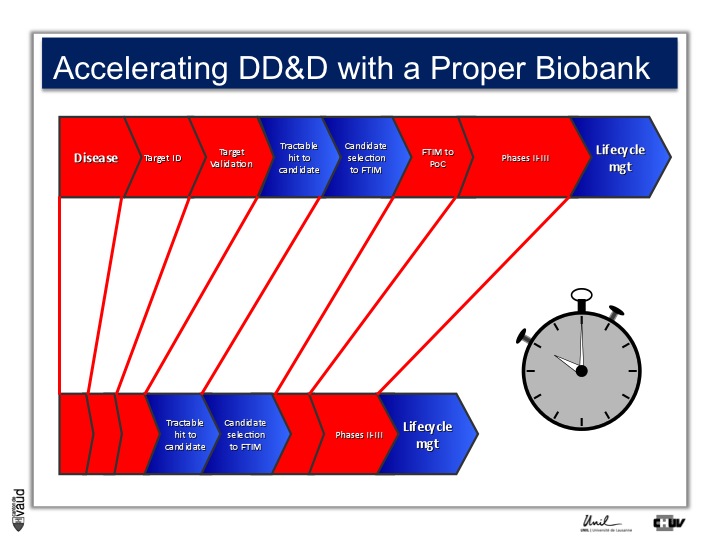
We strategically decided, here at UNIL and CHUV, to invest into this part here of this diagram ; that means building up the infrastructures to have access to data and samples from patients and have the ability to go back to patients, to transform knowledge into clinical utility.
And that leads me to the third part of this presentation, the CoLaus study.
CoLaus: support to drug discovery
The CoLaus study is a population cohort which was originally designed to identify the genetic bases of common cardio-metabolic and psychiatric conditions, with the ambition to identify novel drug targets.
To that end, a total of 6000 adults from the general population here in Lausanne, Switzerland were invited to participate in this study, and were extensively characterised at a clinical level (we talk about phenotype here).
On top of that, DNA from each of these individuals was analyzed using this GWAS technology (also Genome-Wide Association Study) with also 2 million single nucleotide polymorphisms (or SNPs) being analyzed for each of them.
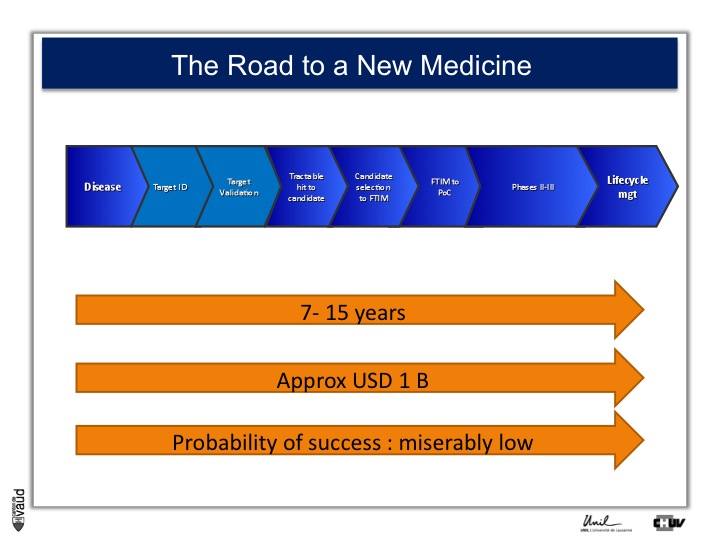
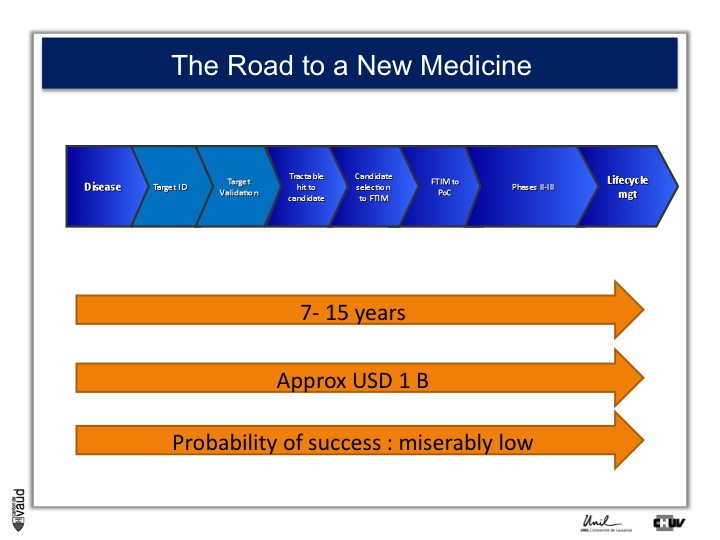
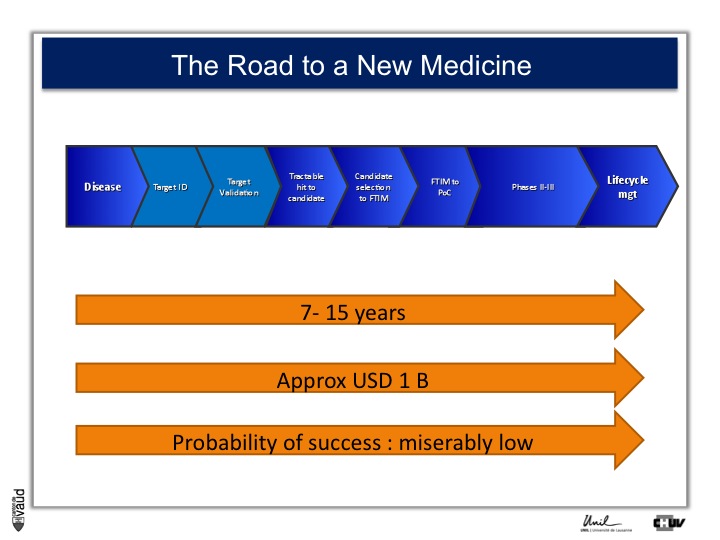
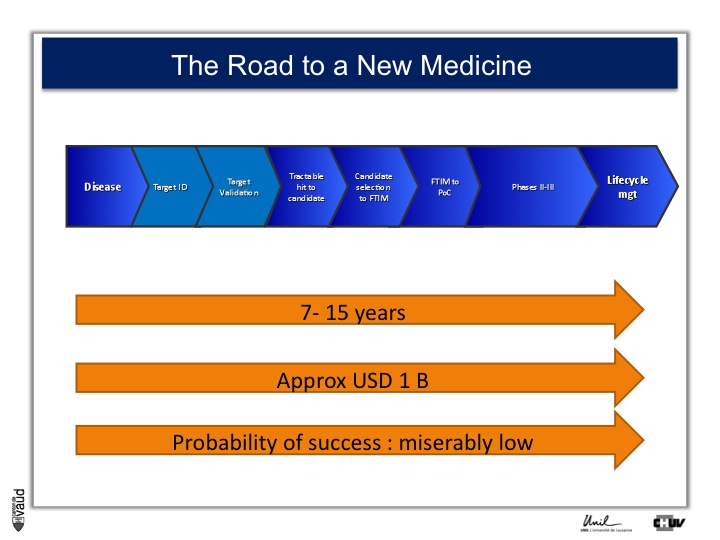
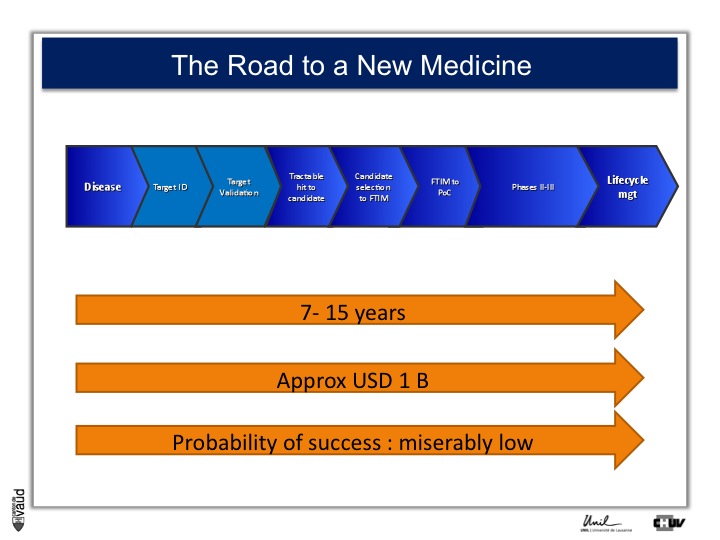
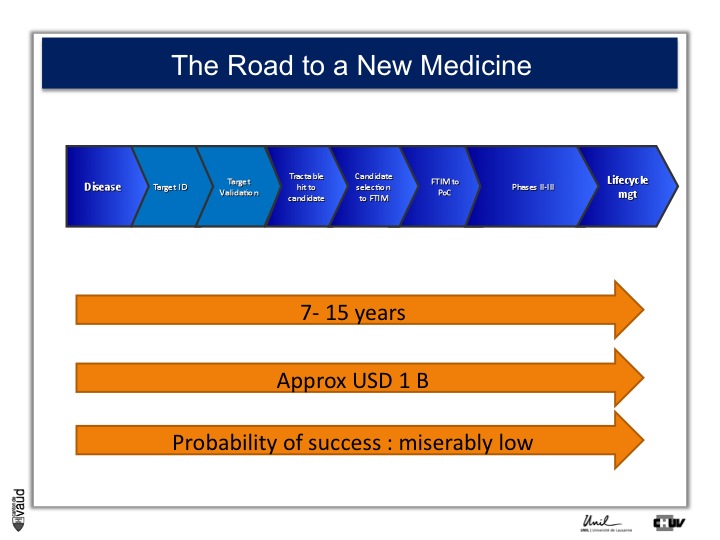
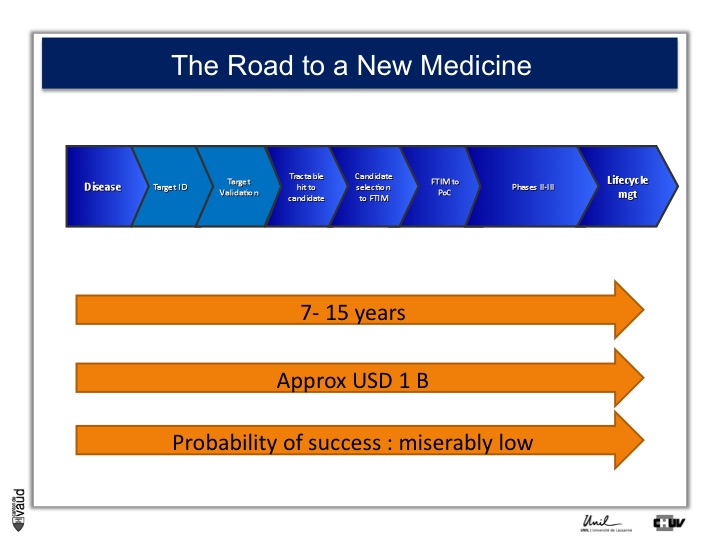
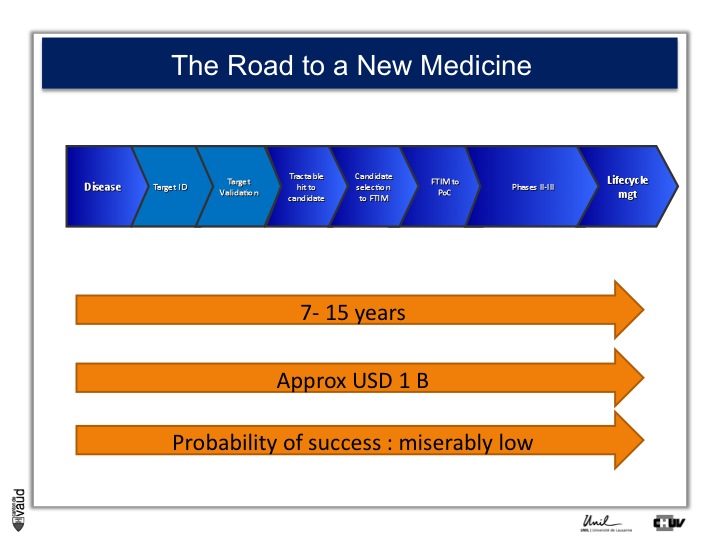
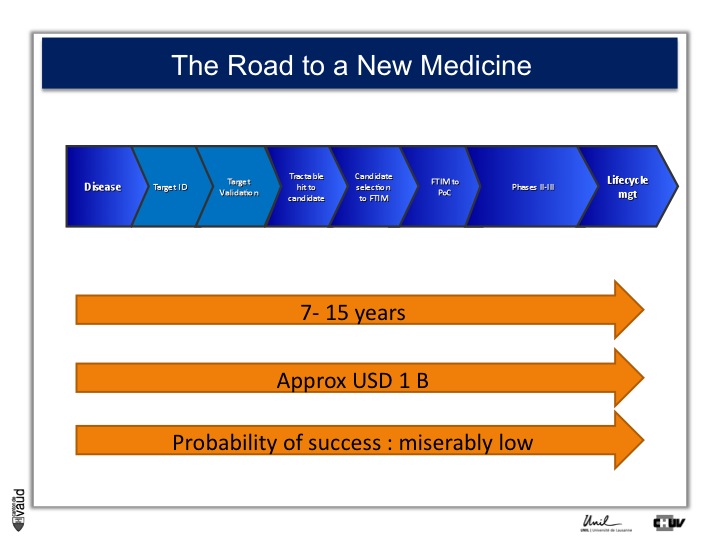
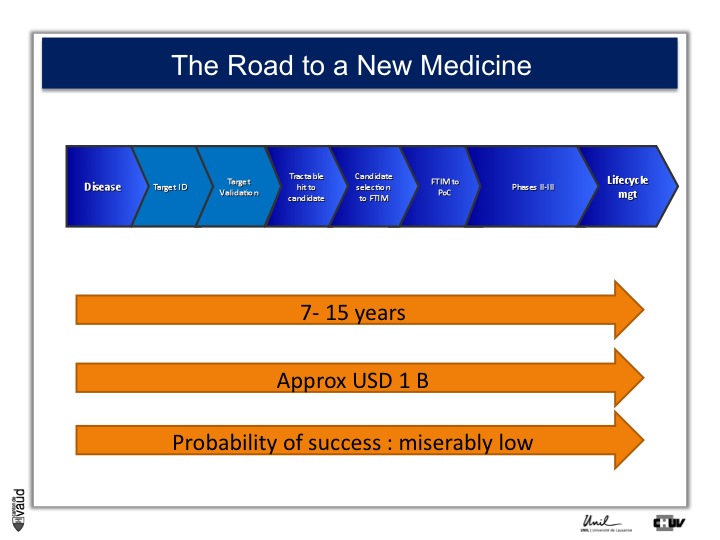
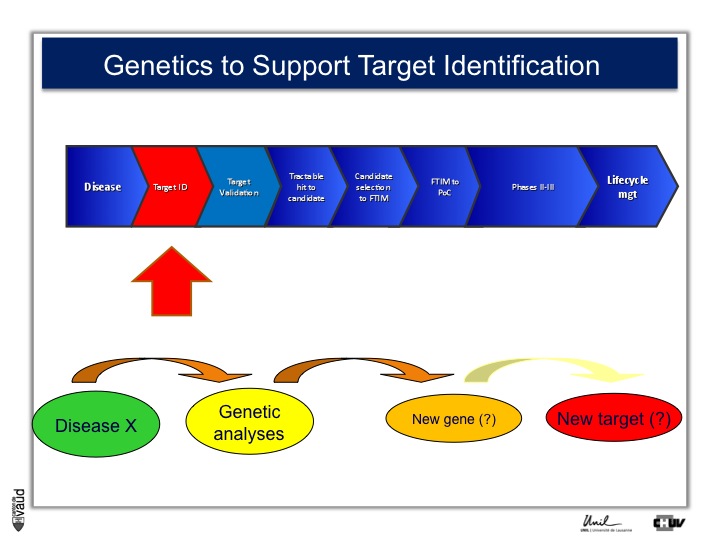
As I mentionned, the idea originally was to find new drug targets, and this is shown on this slide. This slide shows the road to a new medicine.
If somebody wants to develop a new drug, first there is a need to identify which disease we want to go after – let’s say coronary artery disease – then we need to identify a target, that means a protein in the body, usually a receptor or an enzyme, which we want to modulate pharmacologically to prevent or treat the disease.
An example here, if we’re talking about coronary artery disease, would be HMC-CoA reductase, which is an enzyme involved in cholesterol synthesis.
Then, we need to validate this target, which means that we need to generate data which gives confidence that this is the right target for this very disease you want to go after.
And there is a large amount of work at a chemistry level to identify molecules, which would modulate the biological functions of the target, and once a hit has been transformed into a candidate and is ready to go into human, then there is the first time in man study (FTIM).
Once the molecule has been shown to be safe, and the dosage has been identified, then it’s important to demonstrate that the molecule is doing what we are expecting it to do, which is proof of concept, or PoC study.
Once PoC has been reached, then the molecule goes into larger phase II - phase III trials with thousands of participants ; and if you have two studies independently showing the same thing, that means that the drug is effective,
then you can go into regulatory and get your drug approved and reach the market for life cycle management.
It’s estimated that it takes 7 to 15 years for a molecule to go from the very bench to the bedside ; that the costs are approximately a billion dollars, and the probability of success to go from the left to the right is miserably low.
So any piece of data, especially data relevant to humans, is important here and can help make decisions at each of these decision points.
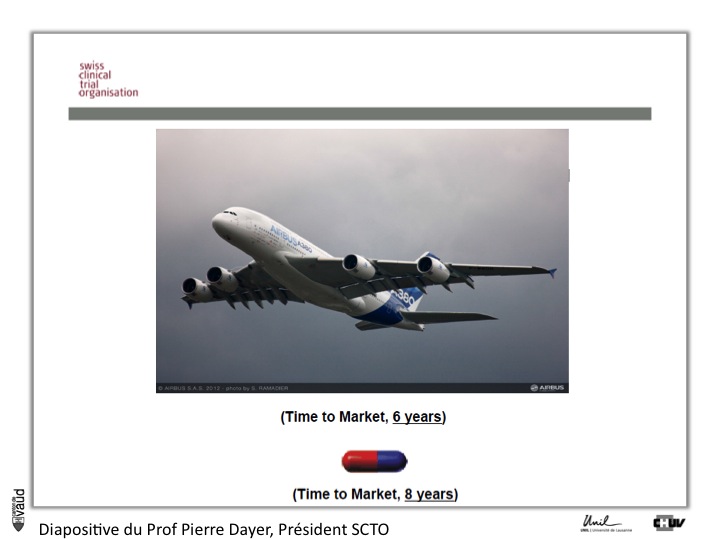
This slide, which I take from Professor Pierre Dayer in Geneva, shows that in fact, if you compare a drug to a plane, it essentially takes more time to the molecule to reach the market as a drug, than a plane.
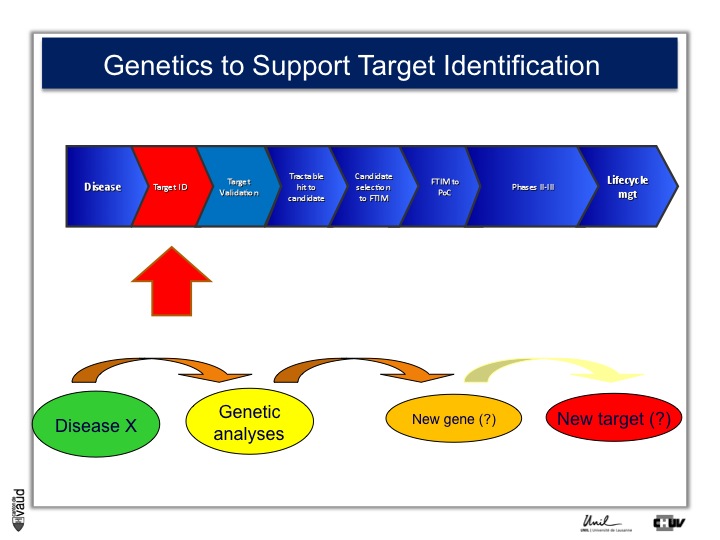
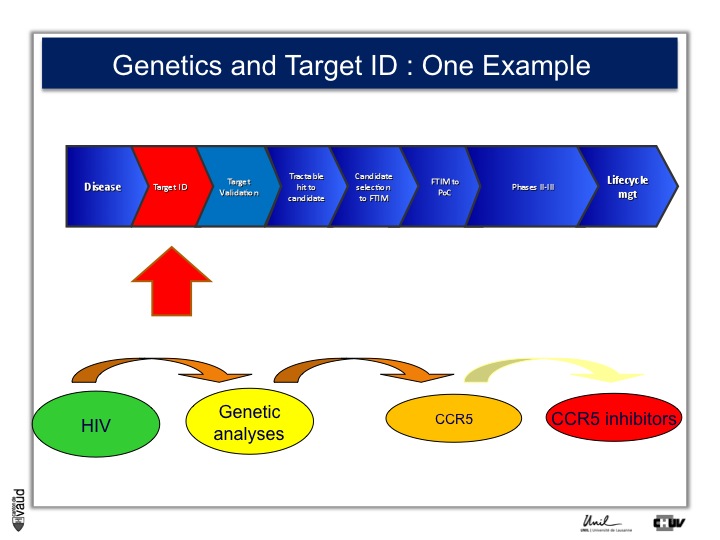
Genetics has been shown to support various steps along this pipeline, and an example is shown here.
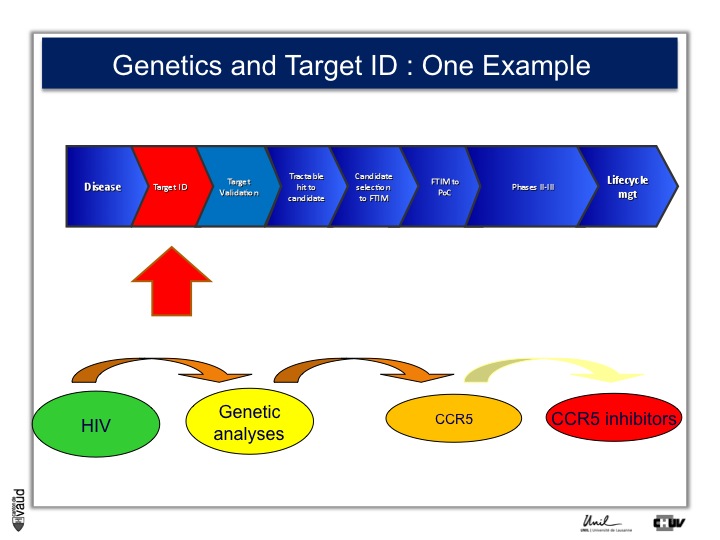
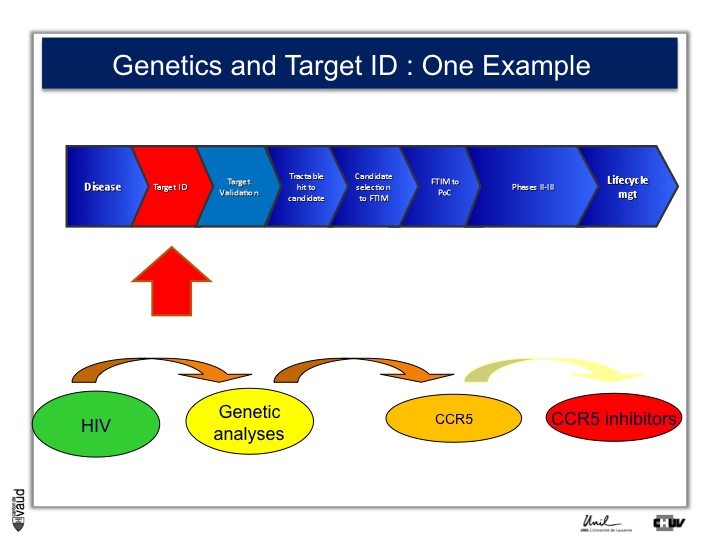
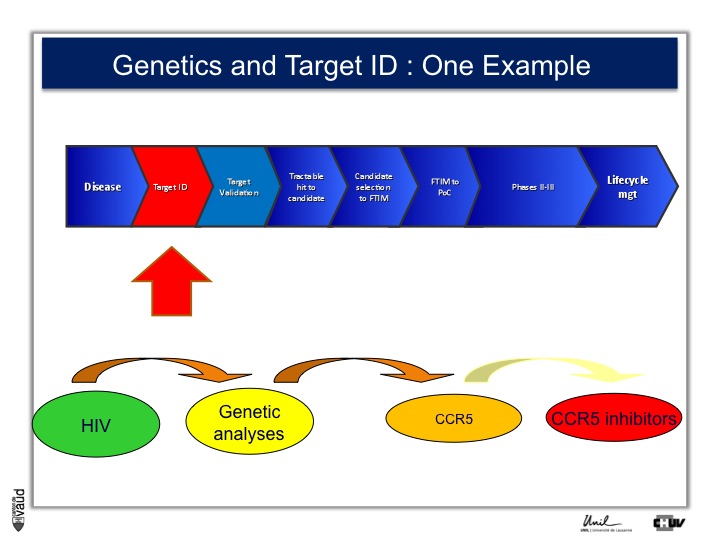
The idea is very simple : you take a disease (like disease X) – again, you can take an example you will see later HIV – you do genetic analyses, you hope to find new genes associated with this disease (susceptibility genes or predictive genes) and you hope to derive out of that new targets and, at the end of the day, new drugs.
This is what CoLaus was designed for. An example to illustrate this approach is HIV ;
there is in HIV a certain number of individuals who are exposed to the virus but don’t develop the disease.
Genetic analyses were performed, back in the late 90s, and identified that one receptor called CCR5 was defective in these individuals who were exposed to the virus and yet did not develop the disease.
And that has prompted the development of CCR5 inhibitors, which are now on the market and constitute an effective drug in the armamentarium against HIV.
The CoLaus team is shown on this slide with Professor Gérard Waeber on the second raw in the left side, and Professor Peter Vollenweider in the first raw.
You’ve here the results of the first genetic analysis that has been published out of CoLaus.
The idea was to identify new susceptibility genes for cholesterol, in particular LDL cholesterol, which is what we would call the « bad cholesterol ».
And what you can see on this slide is the result of this GWAS analysis. The x axis corresponds to the human genome with each of the chromosomes labelled with a particular number, going from the left from the biggest chromosome (chromosome 1) to the sex chromosomes on the righthand side.
There are two millions SNPs, or dots on this plot and for each of these dots you can see on the y axis the strength of association between each particular SNP and the LDL cholesterol levels.
And what you can see is a certain number of what we would call « towers » in this Manhattan plot ; that means dots which are associated with a p-value below 10-6 or 10-8 with LDL cholesterol.
One was very encouraging, it was HMG-CoA reductase, the target of statins, essentially this was important, because it was providing proof of concept that GWAS analyses can identify drug targets.
So, based on these observations, we started looking at the variety of different traits or conditions, and looked at genetic contributions to this make-up.
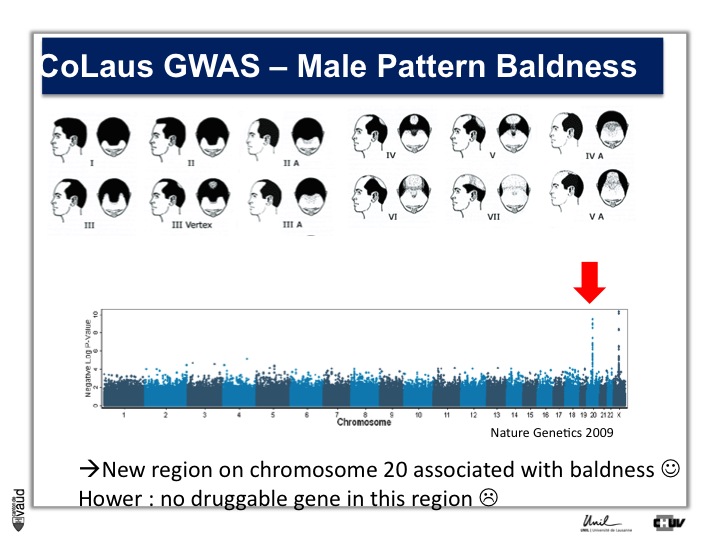
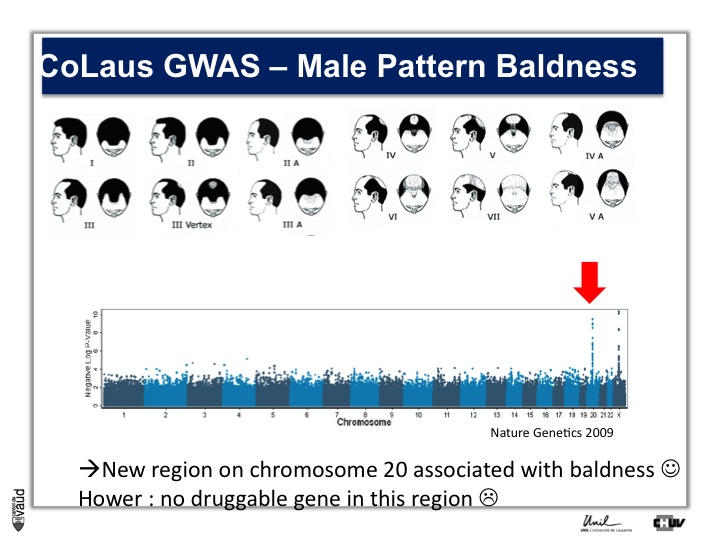
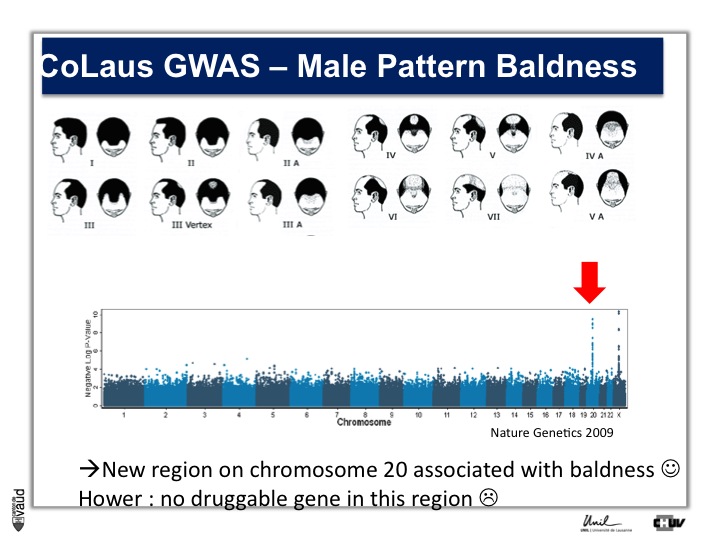
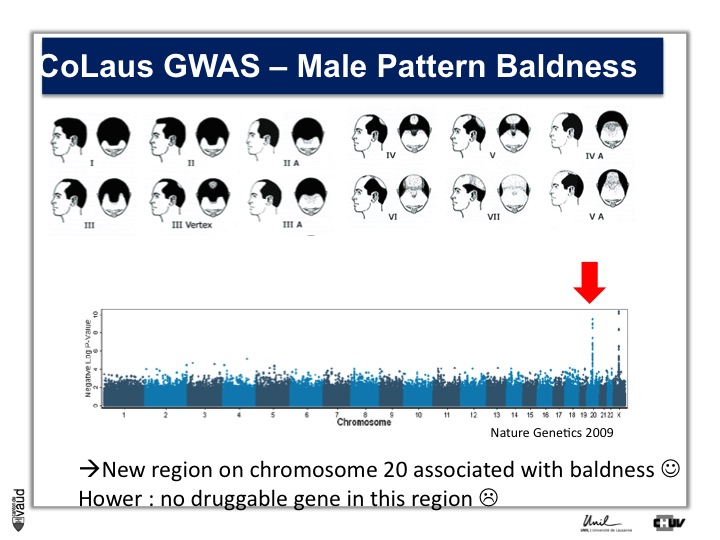
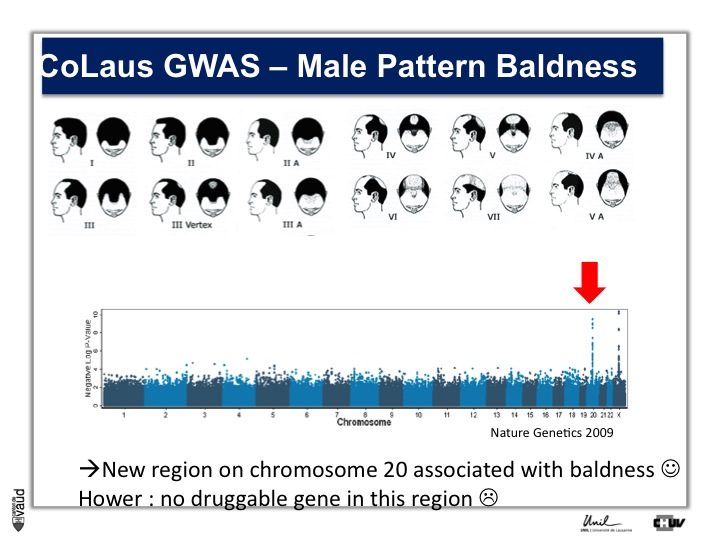
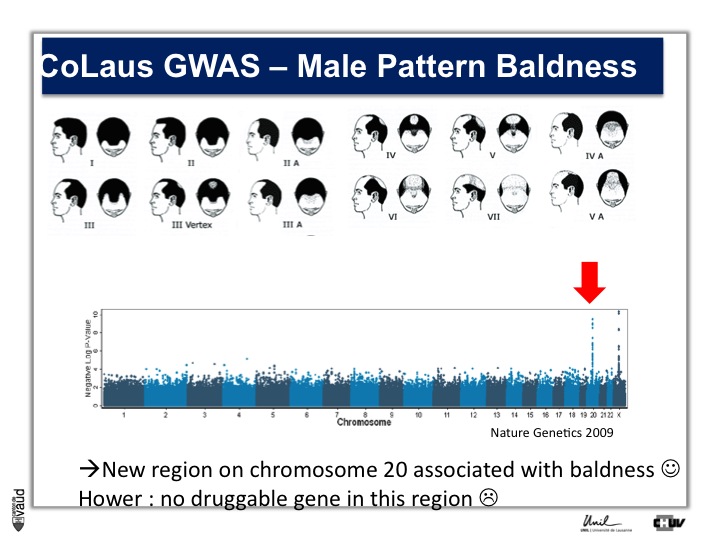
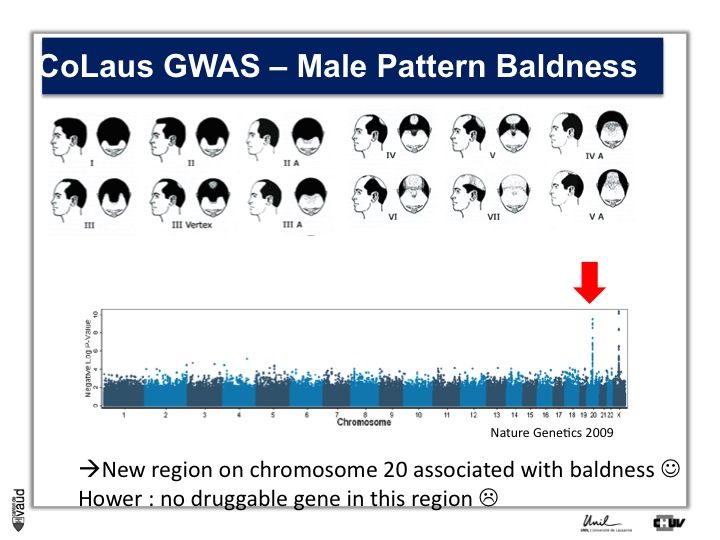
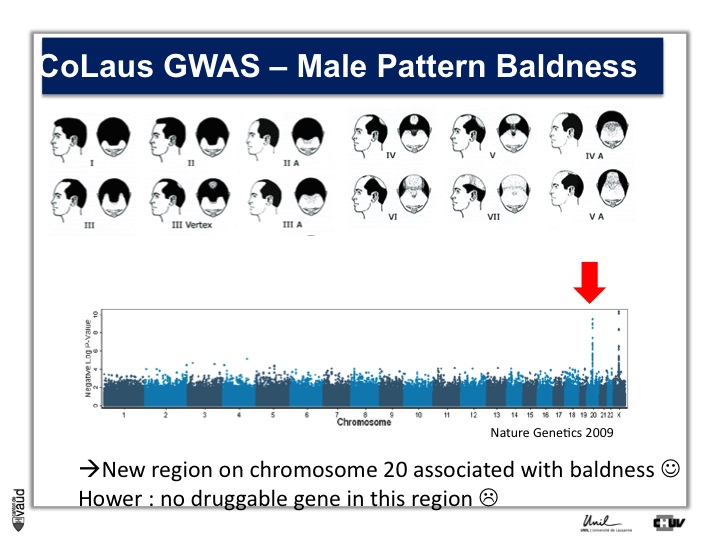
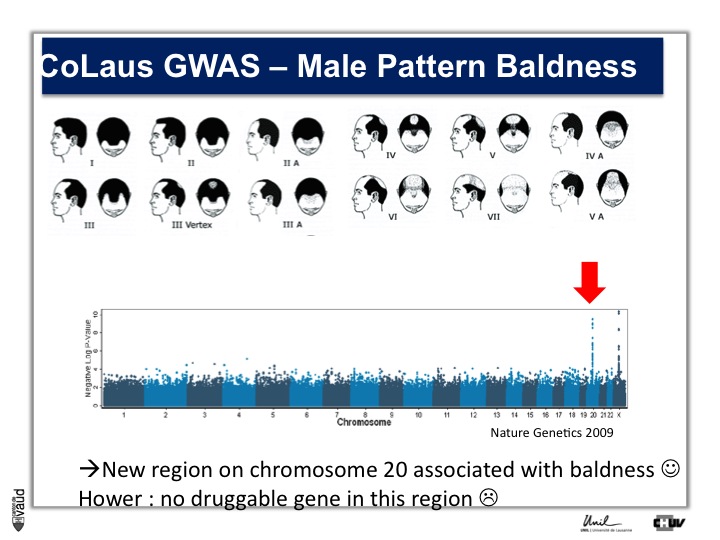
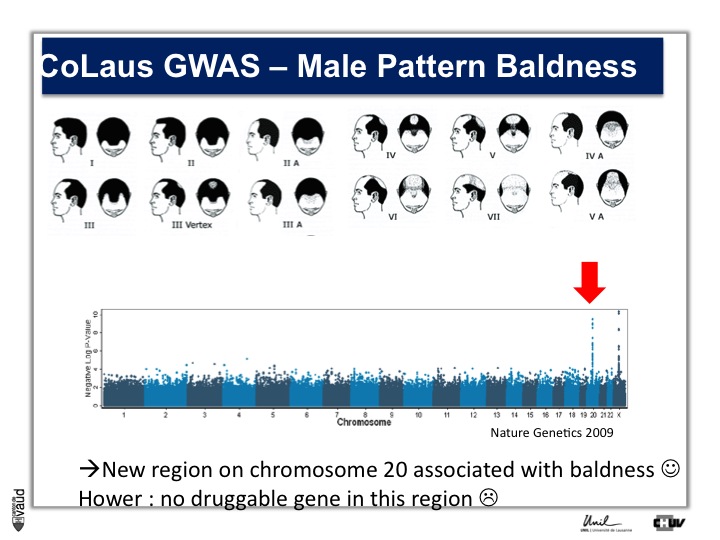
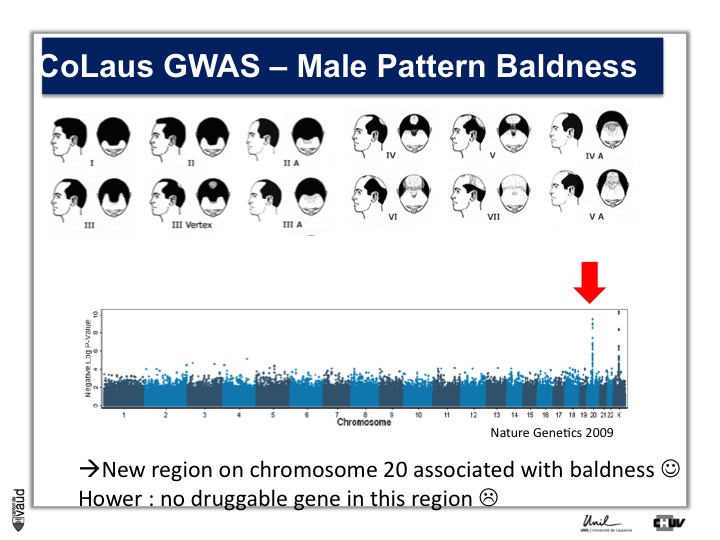
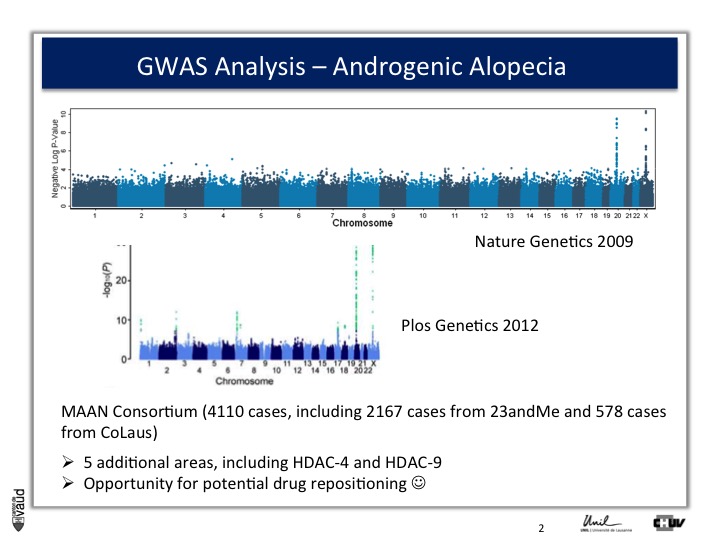
We looked in particular at one trait called « Male Pattern Baldness ». This is not a deadly condition, by no means, but it’s a condition which can have serious consequences and actually people spend more money probably on taking care of their hair than their heart.
And what we asked is « are there some genetic regions in the human genome which are associated with male pattern baldness ? »
To address this question, we took five hundred men who had baldness before the age of 50 and compared their GWAS data with five hundred men with no baldness after age 65 ; and we did this analysis.
What we showed is illustrated on this pannel.
We showed two Manhattan towers on this plot, one on chromosome 20 and one on chromosome x.
The one on chromosome x corresponds to the androgen receptor – that was known – but we found this new region in chromosome 20.
We were very excited about this observation because we were hoping, that this would lead to novel drugs or drug targets.
So that was the good news. The bad news is there is no gene underneath this tower, essentially no gene that could be used as a drug target.
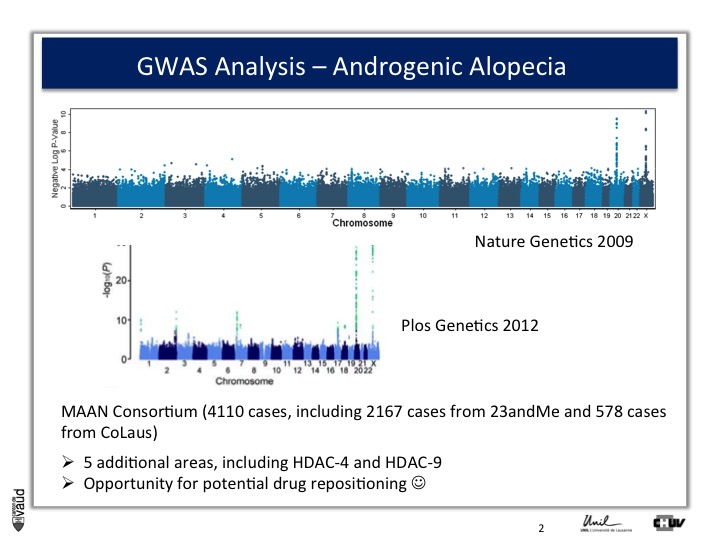
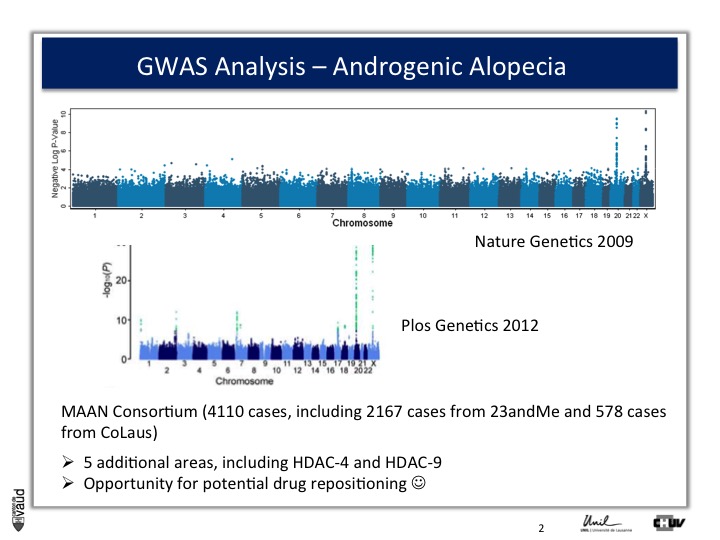
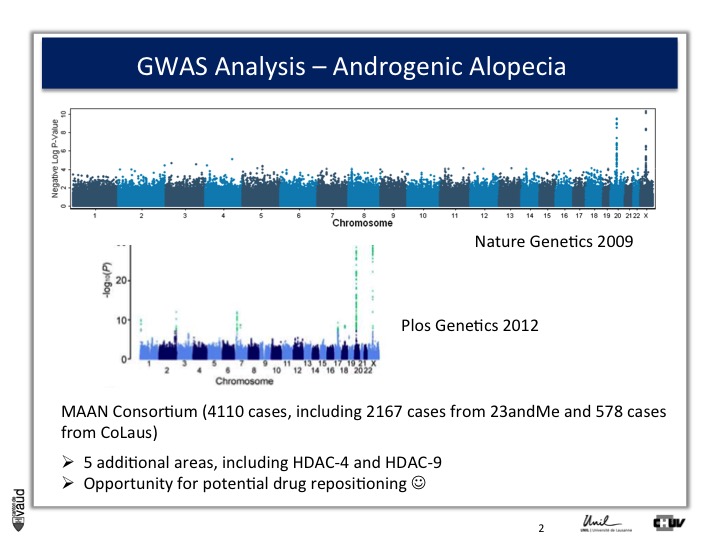
So what we decided to do is go back to another biobank, the one that I talked to you about before, which is 23andMe.
23andMe had GWAS data from 50'000 people at that time. And so, we asked them whether they would be willing to replicate or confirm our observations.
And they were very interested to do so. What they did, and again that‘s showing the power of these IT technologies and biobanks that I was alluding to at the beginning and at the introduction, they sent an email to 30'000 men and asked them, first whether they were bald or not, using this same figure, or scale (the Hamilton scale shown here) ; and a second question, at what time, at what age the condition developed.
And they run a similar analysis and the result is shown here.
Because they had a larger sample size, they not only confirmed our observations on chromosomes x and 20, but also identified five additionnal regions in the genome, which were associated with male pattern baldness ;
And the good news is that two of these five hits actually corresponded to genes which are potentially druggable.
So this is to illustrate the power of the new techologies, the social networks, the direct-to-consumer genetics, and the biobanks taken together.
That leads me to the fourth part of my presentation.
BIL and parallel initiatives: an integrated platform to support biomedical sciences
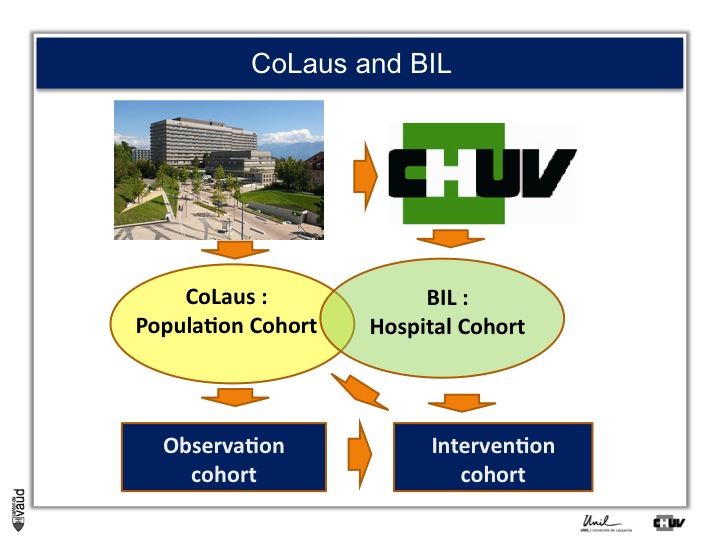
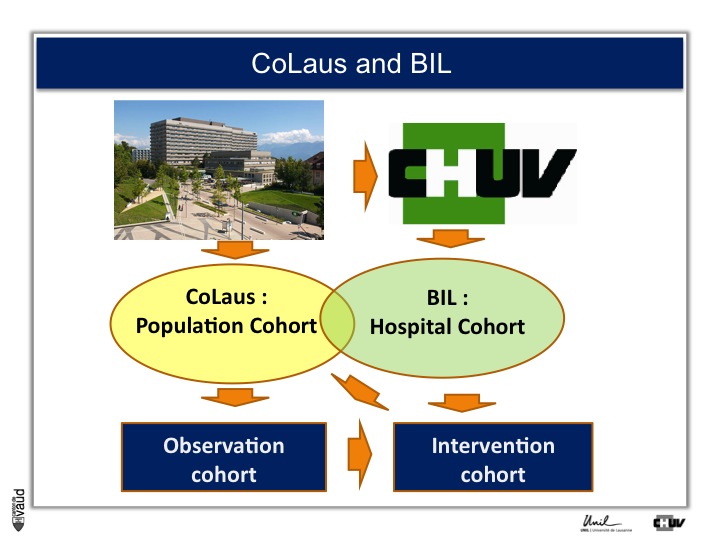
What we decided to do is : CoLaus was an observation study, we decided to build an intervention cohort as well, and this is shown on this slide.
What we decided to do is rather than taking population cohort, which serves to us as observation cohort, invite the patient at CHUV to be part of the Lausanne Institutional Biobank (or the BIL) ; which would serve two purposes, one is as observation and second, as intervention cohort.
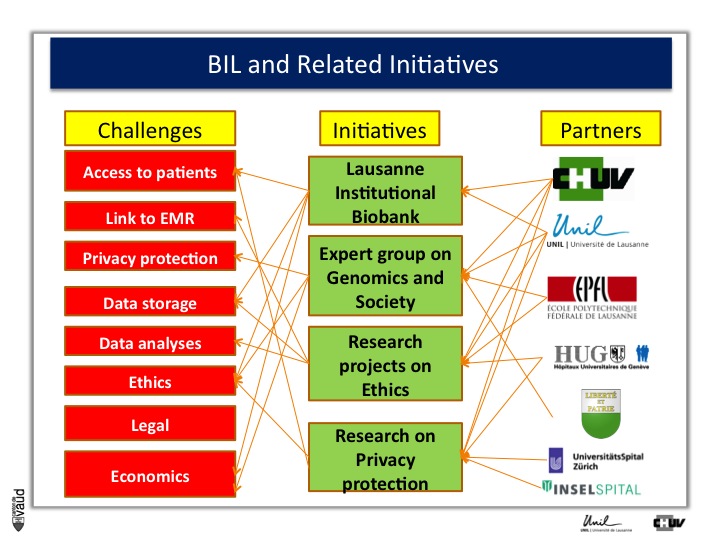
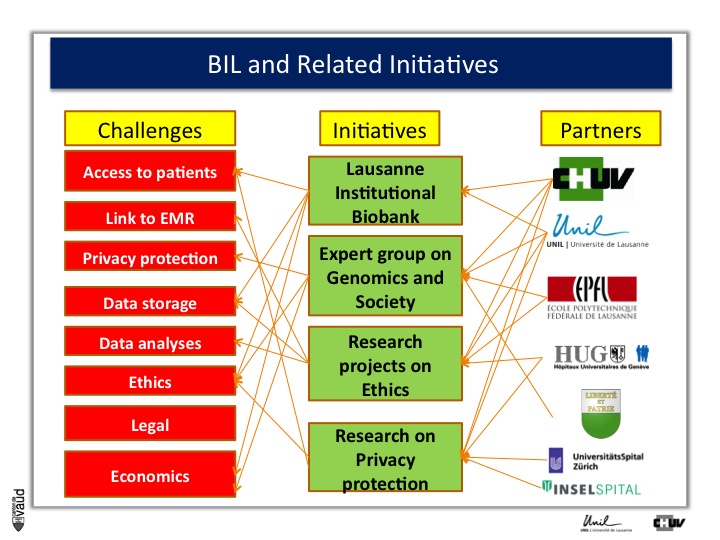
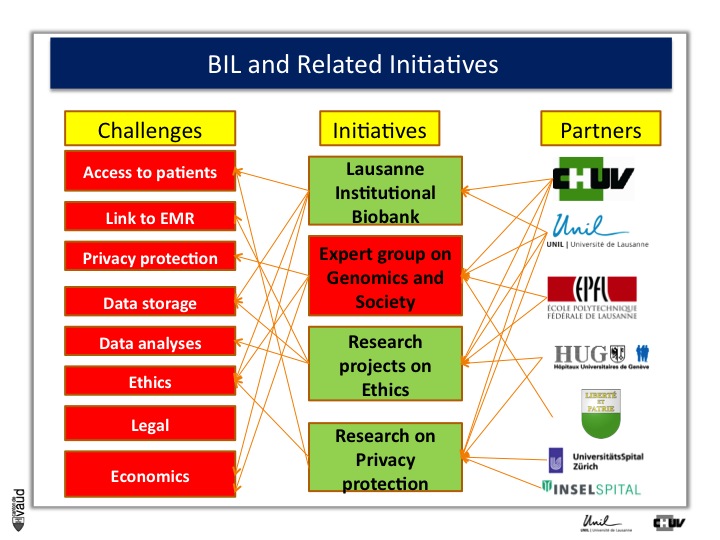
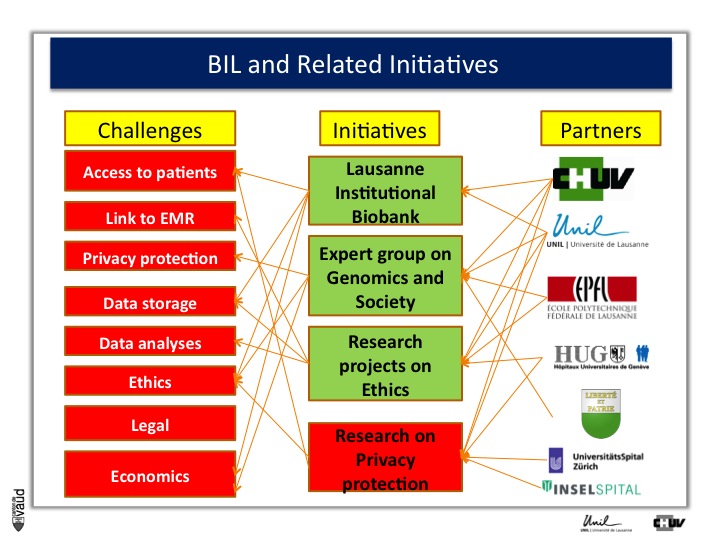
Now, whenever one wants to build this type of biobanks, one has to face some major challenges, which are listed for some of them on the right-hand side of the figure.
First, it’s obviously access to patients, and to patients willing to participate in research. - Again, keep in mind the fourth P of the « 4-P medicine », « participative »-, linked to EMR or electronic medical records, privacy protection, storage of the data, analysis of the data, ethics, legal, and economics.
But the good news was that there are variety of partners in the lemanic area, or Western part of Switzerland, who were willing to be part of this initiative with the CHUV and the University here, the EPFL engineering school here, and the University hospital in Geneva, as well as the ministry of health here in Lausanne.
And what we decided to do, is launch four initiatives which are listed in the middle of this Figure.
The first one is this Lausanne Institutional Biobank, the second is an experts group on genomics and society sponsored by the minister of health here (Pierre-Yves Maillard), the third is research projects on the ethics, and the fourth is research on privacy protection, mostly run by EPFL (I’ll give you some information in a few minutes).
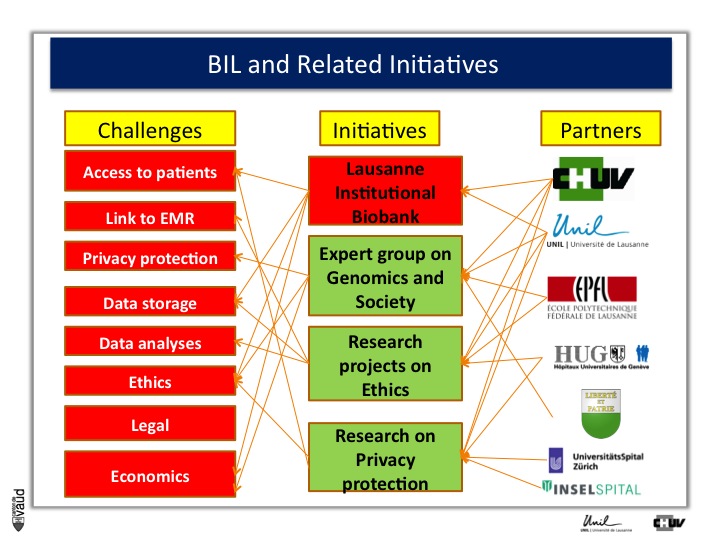
First, the Lausanne institutionnal Biobank.
Again, keep in mind that one of the bottlenecks in the creation of the future of medicine is the access to high quality data and samples.
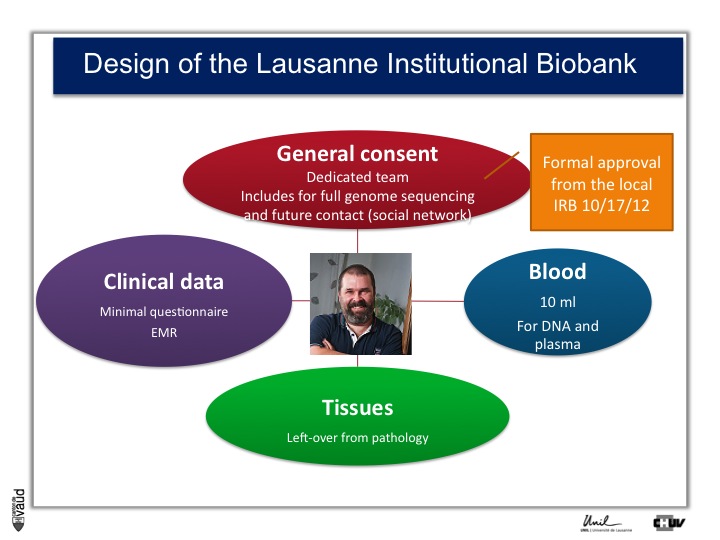
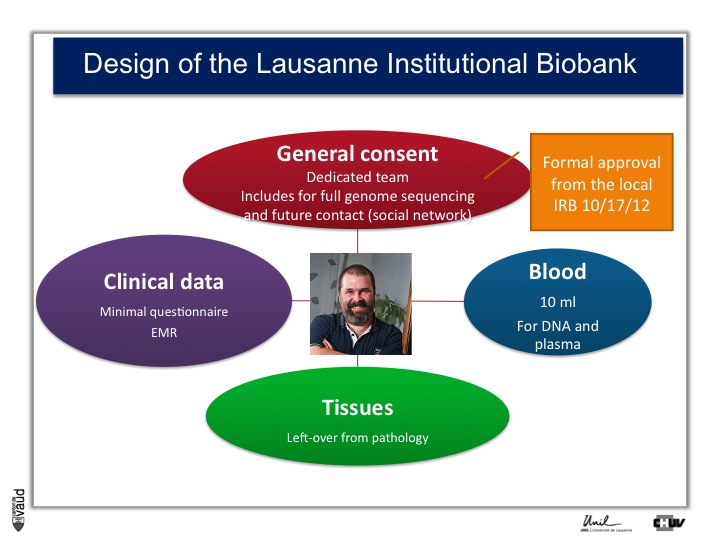
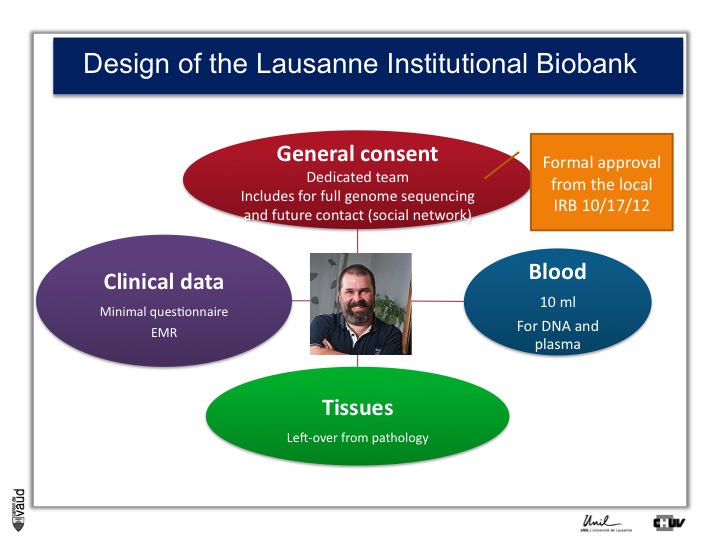
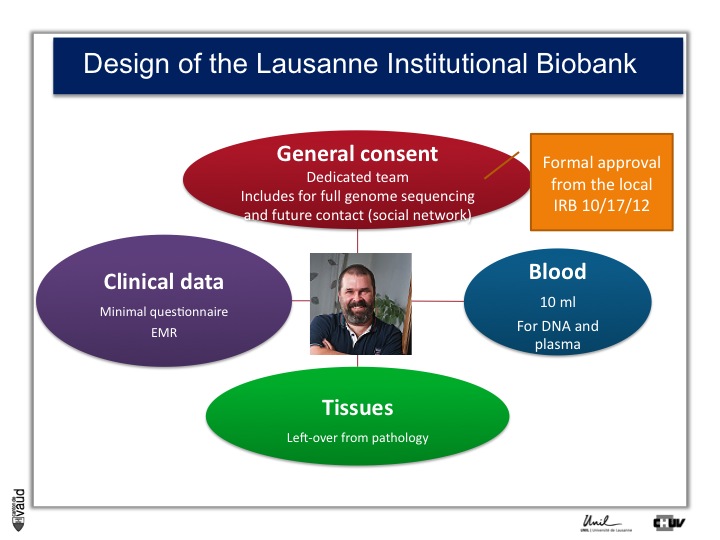
And so what we decided to do is an extremely simple design whereby we’re inviting all the patients admitted in the hospital here to donate us and researchers access to their data and samples for research, including the ability for scientists to sequence their full genome, and the possibility as well to be recontacted in the future, for instance using a social network.
This is called general consent. And this consent and the design of the study was approved by the local canton ethics committee in October 2012.
On top of the consent, what we need is access to clinical data, which is either a minimal questionnaire and the electronic medical records.
We also need blood so that we can isolate DNA for future genetic analyses and plasma ; and we need also tissues, which is mostly leftover from pathology.
The general consent was designed after extensive discussions whith the patients, with the hospital, with ethicists, swiss lawyers, and with the ethics committee, and it was approved; and participants, all patients at CHUV, are now given the opportunity to sign this general consent.
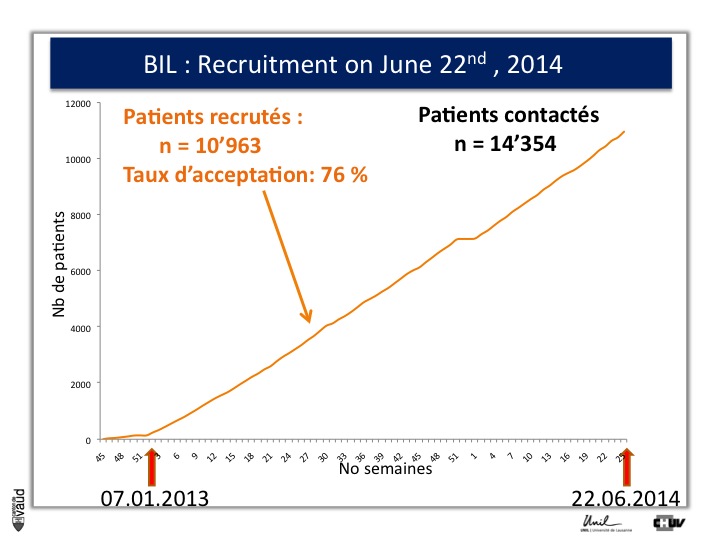
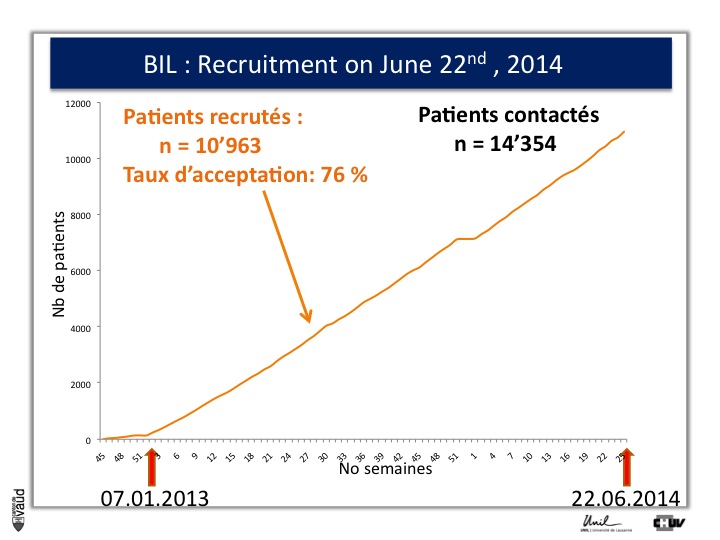
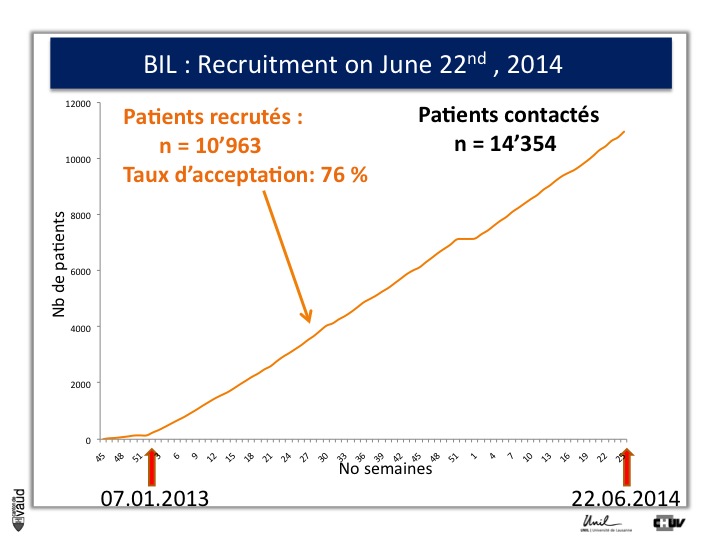
We have created a webside as well, with all the relevant information on our biobank and on genomic medicine (it is in French). And we have started the recruitement on 7th of January 2013.
Over the first eighteen months of the project, we have recruited more than eleven thousand patients, with a participation rate of 76%, which is higher than we had anticipated, and which shows the interest of the patients for this type of genomic research.
I shall also mention that one of the concerns that we had was to biais this high participation rate because patients are in the hospital ; and so to check that, we also sent the consent and the information forms to patients with elective admission and we got a very similar participation rate for those individuals who have the possibility to read the information form and sign the consent before they are admitted in the hospital for elective surgery.
So, what are we planning to do with this biobank ?
Like I was showing before, any type of human data could be useful to accelerate drug discovery and development and similarly as well for biomarkers.
And so one of the ambitions here is to use the biobank in the same way we have been using CoLaus : to accelerate this process and increase the probability of success.
This is one particular example of study that we have in mind.
There is a gene called LRRK2 which predisposes people who have a particular mutation within this gene to Parkinson’s disease.
This is a change where one amino-acid at position 2019 is substituted by this mutation to a different amino-acid.
And the probability of carriers of this mutation to develop Parkinson’s is approximately 70% by the age of 70.
This mutation changes the function of this enzyme LRRK2 and increases its activity so that industry is now developing inhibitors to this particular protein which is a kinase.
We hope that these kinase LRRK2 inhibitors will go into humans soon, and then can be tested to show that they either prevent or treat Parkinson’s in carriers of this G2019S mutation.
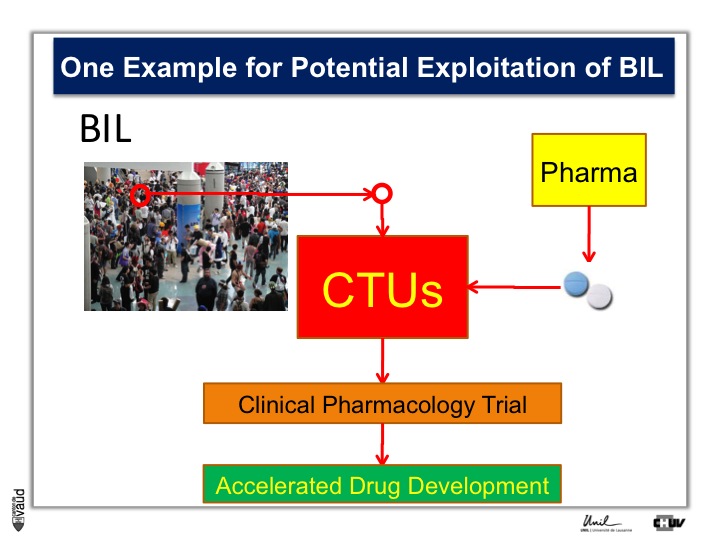
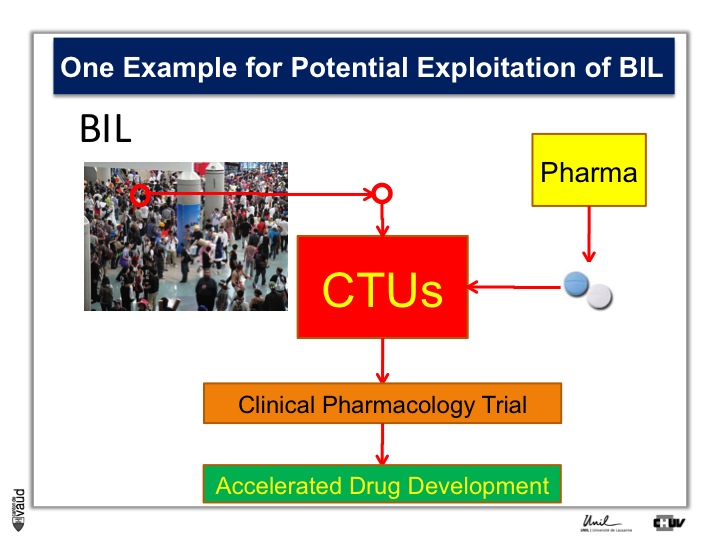
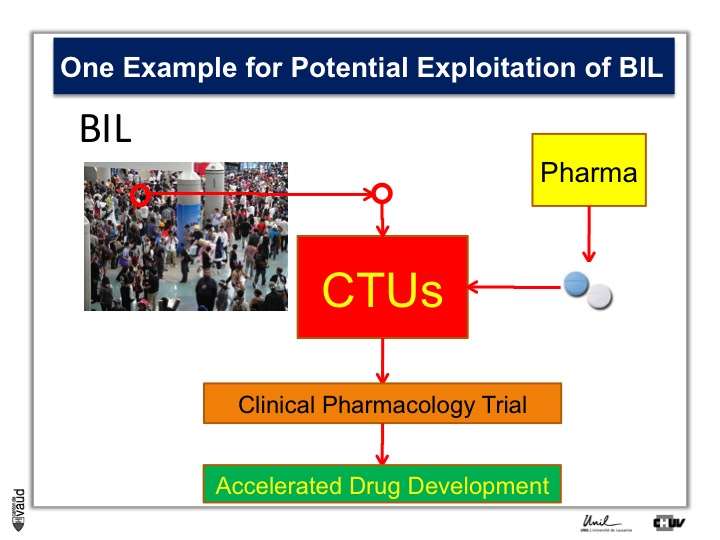
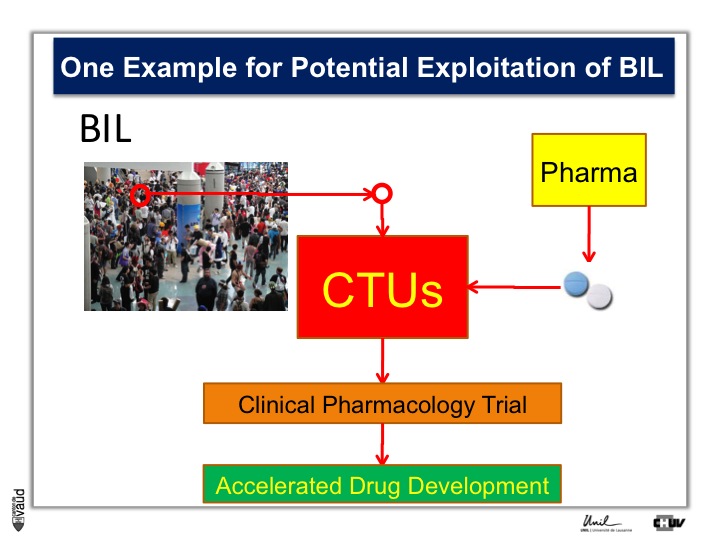
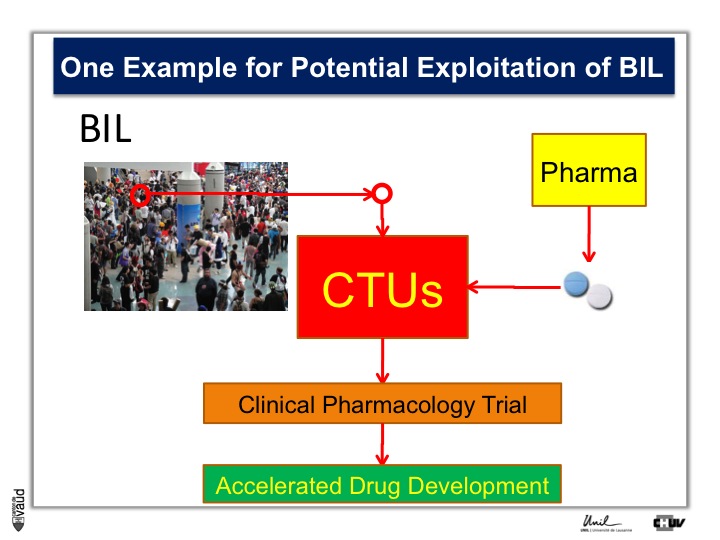
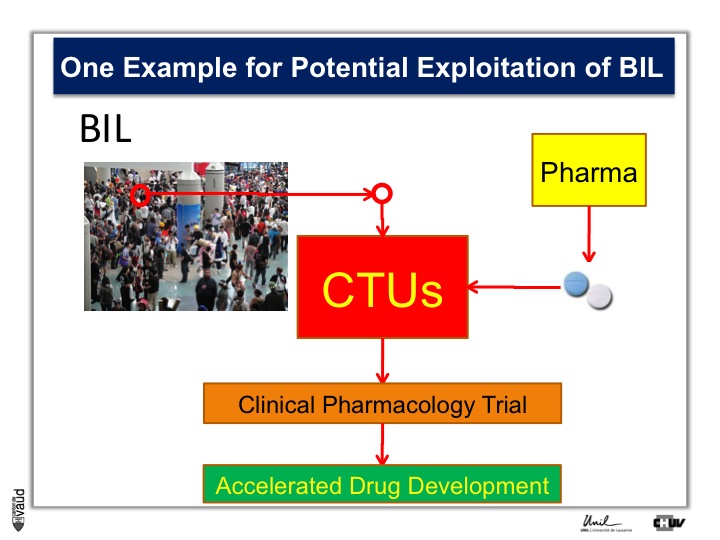
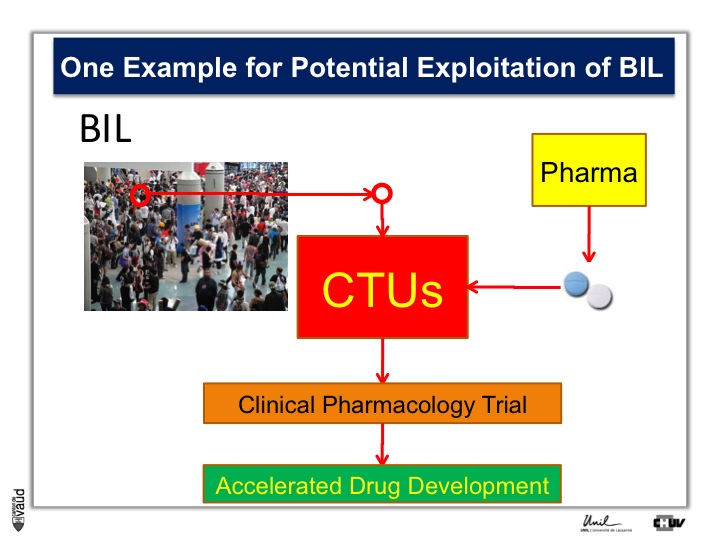
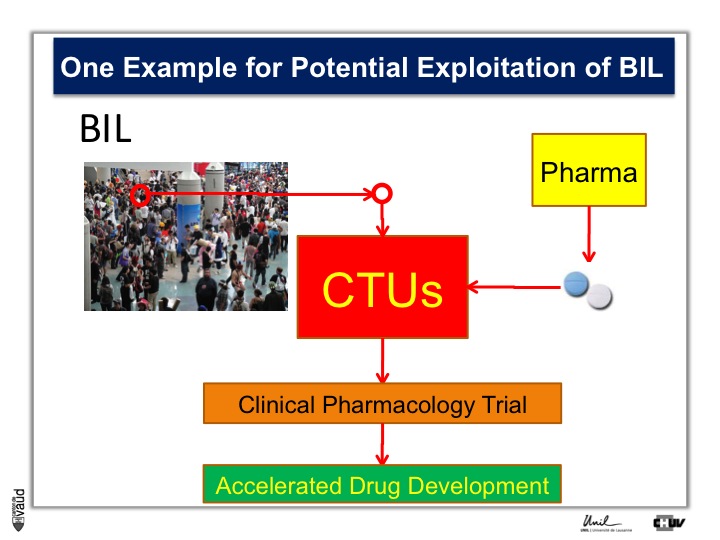
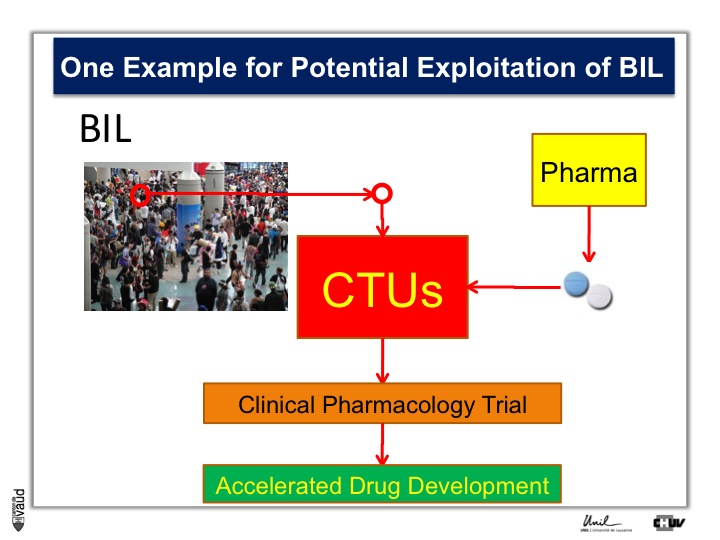
To do that, what we need is patients, Parkinson’s patients who have this mutation, it’s only about 5% of the Parkinson’s patients who carry this mutation.
And so the idea here is that in the biobank, we will be analyzing this particular mutation, and so we will be in a position to identify the carriers, and we will invite these carriers for being part of clinical trials with these new kind of LRRK2 inhibitors.
So they will be invited to come to the clinical trial unit here, or CTU, and participate in clinical pharmacology trial, so that if we have already these patients, identified and willing to participate in this trial, we can really accelerate the process of drug development.
Now, to make it happen, the institution here (that means CHUV/UNIL) have decided to create what is called the « plateforme de soutien à la recherche clinique », which means a platform to support clinical research in Lausanne.
It has three pillars : one is an IT group, the second is the biobank and the third one is the clinical research center.
This is perfectly aligned with the development plan of the University, and the strategic plan of the hospital ; and is run with a single gouvernance.
So, I’ve been talking about the biobank, now a couple of words on this expert group on genomics and society ;
Again, this was an initiative which was sponsored by the minister of health, Pierre-Yves Maillard, and which led to a document called « Sequencing of the human genome : realities, opportunities and challenges for public health in the Canton de Vaud » – the canton around Lausanne.
It’s an initiative with senior representatives in this working group from the University, the hospital here, the engineering school, and the local medical society.
Lastly here, research project on privacy production. Genetic data are sensitive material ; and I’ve taken here a cartoon which you may have seen, which is quite funny, where you’ve got this guy delivering the pizza to this gentleman and saying « we checked your confidential medical records (which would also be genetic, by the way) on the internet. Cheese and anchovies would be bad for you, so we left them off ». We don’t want this type of things to happen.
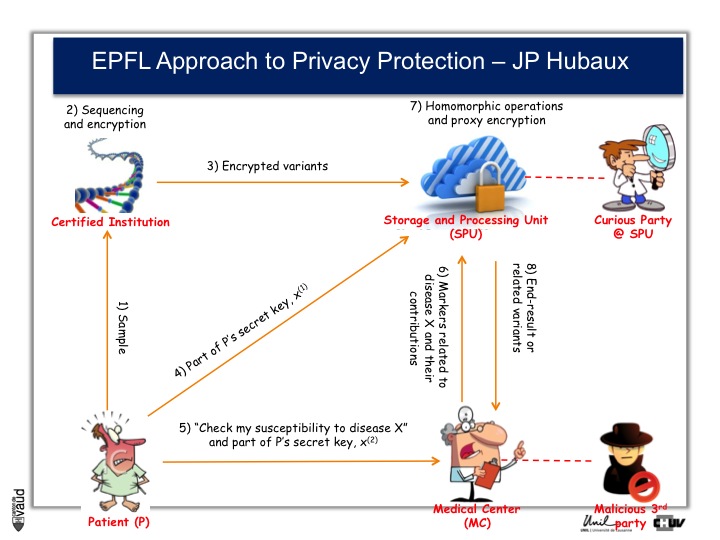
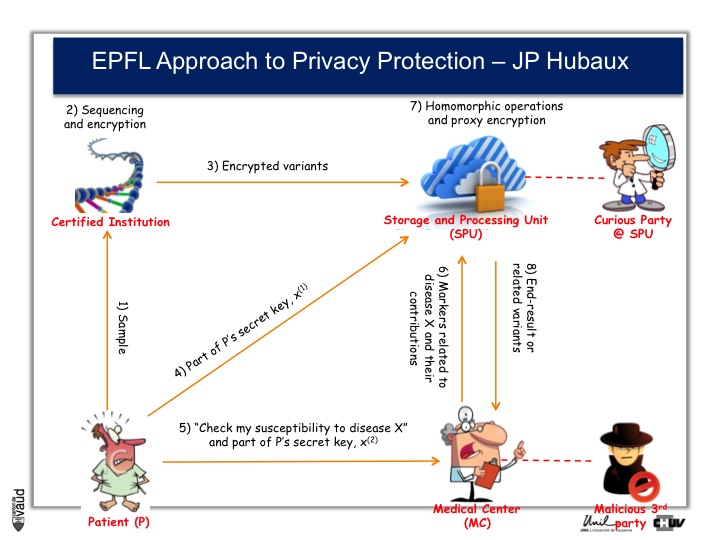
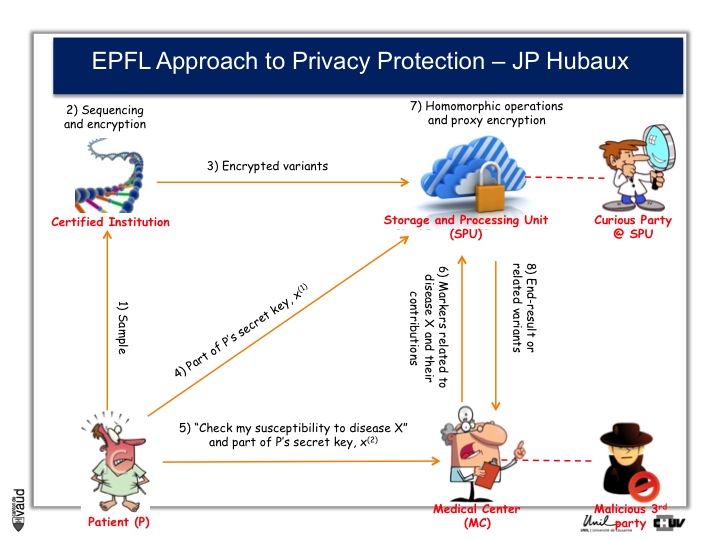
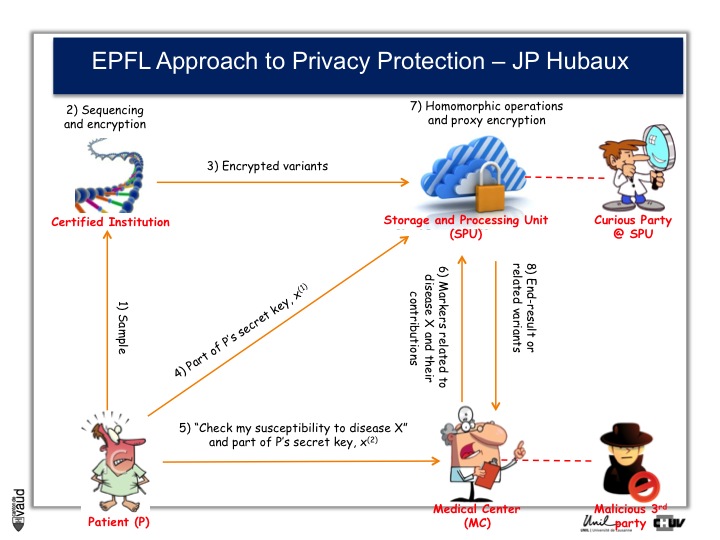
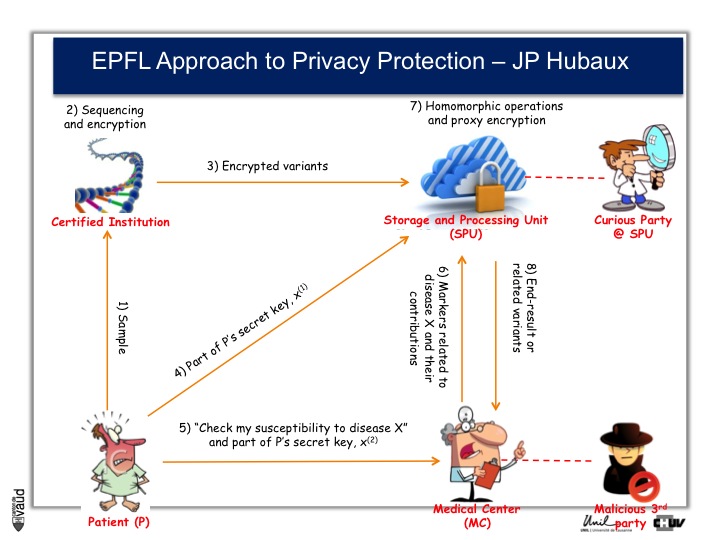
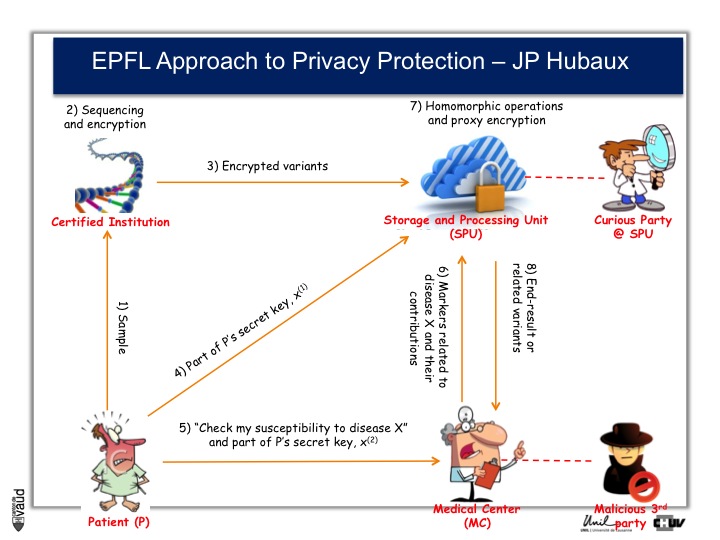
And as a way to prevent that, Professor Jean-Pierre Hubaux at the EPFL, and his team, are creating now a new way of protecting genetic and genomic data.
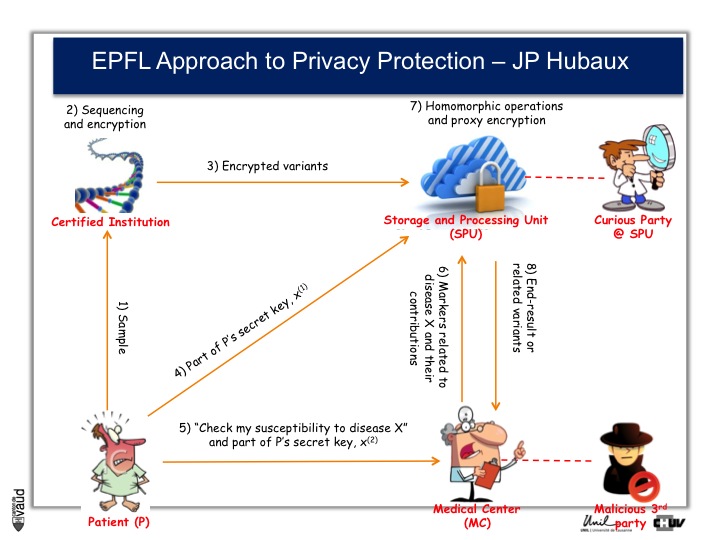
And the process by which they are working is illustrated on this slide.
At the bottom left, you have got this patient ; the patient sends his DNA material, or his doctor, to a certified institution that would do the genetic analyses, for instance sequencing and would encript the data.
The encripted variants are then sent to a storage and processing unit where some sophisticated encription procedures will be performed.
Now doctors, upon request from the patients, would have access to part of the data.
So, imagine again that we are talking about an HIV patient, imagine that the doctor is an HIV specialist who wants to prescribe Abacavir. What he can do is interrogate the cloud and ask « does this patient carry the HLAB7501 mutation ? »
If he does, and this is the only piece of information he will get from the cloud, then he will not prescribe Abacavir. By doing so, he will not have access to any data (genetic) pertaining to other disorders like Alzheimer‘s for instance or cancer. He will only interrogate this very marker, which has been shown to be associated with the side effect of the drug he wants to prescribe.
By doing this encription, there is also the possibility to prevent curious party, or malicious party, to essentially go into this data bank and make sense out of these data, so that the privacy of the patient is optimally protected.
Finally, I want to emphasize the fact that this biobank and these initiatives are part of a larger broader regional initiative called the Lemanic Center for Personalized Health, which is under construction in the lemanic area (Vaud, Genève), with also the Swiss Bionformatic Institute.
Conclusion
Finally, the conclusions of my presentation ;
First, biobanks are essential for biomedical research and for the development and implementation of medicine 2.0 ;
The biobank in Lausanne has been specifically designed for this latter goal – that means the implementation of medicine 2.0.
We designed an innovative and integrated approach : innovative because we are not aware of any similar initiative in its design in Europe or other parts of the world.
This is a long-term investment and we anticipate that the biobank and the platform with the IT group and the CRC should be fully operational to support a broad range of translational research projects by 2017.
I really want to finish up this presentation by thanking and acknowledging here the contribution of several people : first, the patients at CHUV who agreed to participate in the BIL project,
Second, the team under the leadership of Christine Currat, who has done all these recruitment and put in place this infrastructure.
And thirdly, I want to thank the Rectorate of the University and the general management of the hospital here, for sponsoring and founding these initiatives.
In parallel, I want to thank the participants of the CoLaus study, Gérard Waeber, Peter Vollenweider and Martin Preisig, who are the clinical leaders of this CoLaus programme.
And GSK and the Swiss National Science Foundation for the funding of CoLaus, original recruitment and follow up visits. Thank you.



















































 http://www.chuv.ch/biobanque
http://www.chuv.ch/biobanque